これだけは知っておこうTLS
記事について
セキュリティのためにTLSを導入しようとはよく聞くが、 そもそもTLSは何を担保するものなのかを整理する。
前提として知っておくべきこと
- デジタル署名
- デジタル証明書
TLSは何を担保するのか?
下記の3つを担保する。 つまるところ、man in the middle攻撃への対策となる。
- 正真性
- 改ざんがなされていないこと
- 機密性
- 通信盗聴されても大丈夫なよう暗号化されていること
- 認証
- 正しい相手と通信をしていること
TLSの通信の流れ
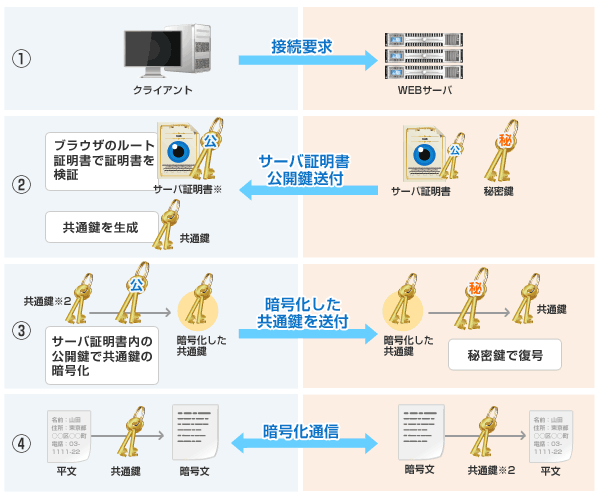 引用: SSL暗号化通信の仕組み
引用: SSL暗号化通信の仕組み
クライアント -> サーバ
- 接続要求をおこなう
サーバ -> クライアント
クライアント
サーバ
どうやって3つの目的を担保しているか?
- 認証
- デジタル証明書と共通鍵によって想定通りの相手と通信していることを担保する
- 機密性
- セッション鍵による共通鍵方式の暗号化通信により、機密性を担保する
- 正真性
- 暗号化されたデータにMessage Authentication Codeというデータのハッシュ値を付与し、これを受け取った側がハッシュ比較することで担保する
mTLSについて
厳密には上記のTLS通信だけでは認証の要件を担保できないこともある。 たとえば、企業間の外部公開されていないシステムを連携させるような、少しセキュリティ要件の高いケースなど、 サーバにアクセスしてくるクライアントもちゃんと保証したいようなケースである。 そのときに使うのが相互TLS通信というものである。(以下mTLS) mTLSはサーバに加えて、クライアントにも証明書を要求することでクライアントの身元を保証することができる。
ルート証明書、中間証明書、サーバ証明書
【2019】フリーランスエンジニア活動 振り返り
趣旨
2020年が始まるので、 2019年にやったこと、アウトプット、反省点をまとめ、翌年の指針を整理したいと思う。
前提
フリーとして働く、インフラとバックエンドを専門とするソフトウェアエンジニア。 現在は法人成りしていて、請負でベンチャー企業で開発の仕事をする傍ら、自社製品の開発に勤しんでいる。
請負でやったこと
- GAE + Go + CloudSQLを基本構成としたBtoCサービスの開発
- Stackdriver Monitoringの技術検証
- GAEで作られたパッケージシステムをスケール性を加味しGKEに移行
- 企業が使用する管理システムにAuth0をつかった認証認可の仕組みを導入
- Datadogの導入
- 機能検証
- AWS Elastic BeansTalk + Ansible
- SLOの策定、SLOにあわせてパフォーマンス改善
自社サービスとしてやったこと
- 3月 「ルーチンタイマー」iOS版リリース
- 10月下旬 「ルーチンタイマー」がツイッターで話題になりDAUが激増
- 11月中旬 急遽「ルーチンタイマー」Android版を開発開始しリリース
- 11月15日 法人設立
- おたくま経済新聞様にルーチンタイマーを紹介いただきました
- 朝日新聞様にルーチンタイマーを紹介いただきました
ブログアウトプット
振り返り
法人経営の大方針として、 ソフトウェアエンジニアとして安定したキャリアを築きつつ、余剰時間で他方面の収益源を作るべく活動している。 つまり経営の健全性としてはざっくりと
- エンジニアとしてキャリアになる経験が積めているか
- 単なる開発以外の事業の収益
を追っていこうと思っている。
エンジニアとしてキャリアを積めているか?
フリーランスが生き残るために必要な要素の一つはスペシャリティだと思っていて、 自分はバックエンド、インフラエンジニアとしての専門性を高めることに注力している。 そういった意味で、オンプレ畑で育った自分がGCPもAWSもバランス良く設計から開発、運用まで携われたのはとても良かった。 さらに、今年は運用において重要な監視について検証導入運用まで関わることができ多くの知見を吸収することができた。 今後はよりアーキテクト力を高めるために、引き続き開発から運用までまるっと経験でき、裁量の多い現場を選択して修行していくつもりである。 (運用まで視野にいれるなら一つの現場で最低1年は働きたい)
また、最近のバックエンドの開発は要件に対して過剰にk8sやマイクロサービスを導入したりとオーバーエンジニアリングが目立つ気がしている。 そこを意識した上で地に足のついたアーキテクトを目指していきたい。
単なる開発以外の事業の収益
今年はリリースしたアプリ、「ルーチンタイマー」で少し収益が出始め、大きな一歩を踏み出せた年だった。 Twitterでバズリ、メディア掲載を受けたのが利き、狙ったとおりのユーザ層に訴求することができた。 徹底的なユーザ目線、とはいいつつも実際にそれを体現するのは難しい。 だがパートナーがこういった領域が大得意で、パートナーに基本的に従えば良いものができるということを実感できた。
また、そもそも自社サービスはまずリリースさせるまでが難しい。 そういった意味で今も運用し続けられているプロダクトを2本出せたのは大きい。 成功要因は、
- 工数管理
- パートナーへの定時進捗報告
- なにかしらモチベーションをあげる技術要素を一つだけいれてみる
ということがわかったので、これから開発する新プロダクトもこれらを意識していきたい。
課題としては、良いものを作っても集客についての方法論が見いだせておらず、 バズって認知されればある程度ユーザがついてくれるのはわかったが、 そもそも流入をふやしたり、安定させるまでに至っていない。 2020年はまずリテンションを上げた上でさらに流入を増やす施策を打っていく予定である。 また、別収益源としてエンジニア養成スクール事業などにも手を出そうと考えている。
働き方の改善点
5月〜7月の間、複数の仕事を抱えすぎて体調を崩し、8月、9月はまったく働けない状態、10月以降は請負の開発を週3に減らす自体になってしまっていた。 しかし自分のキャパを把握することができ、3つ以上仕事を抱えるとあふれることが分かったので、 2020年は週4請負開発 + 週3で自社事業に取り組む方針で活動するつもりである。
なるべく一つの現場で定着して成果を出していきたいので、合わないと感じた場合は損切りの意思決定を早く持たないと精神力、時間が削れられる。 良い現場で長く働くためにもムダを減らしていくように行動しようと思う。
2020年もがんばるぞーー
Firestore + BigQueryで簡単なログデータ&プッシュ基盤をつくった話
導入
アプリのイベントログや、DAUなどの集計を考えるときに真っ先に選択肢に上がるのがFirebase Analyticsだ。 ユーザを特定のセグメントに分割して扱い、セグメントごとにプッシュ通知を送ったり、 特定のIn App Messageに対する特定のイベントへのコンバージョン率を自動で集計してくれたりと、 Firebaseの他のツールと連携がシームレスにできて良い体験ができる。 だがいろいろと制約もあり、より詳細な分析を行いときには実現できないこともあったので、 イベントログをFirestoreに飛ばし、BigQuery連携することで独自のログデータ基盤を構築したのでまとめる。
対象プロダクト
- スマホアプリ
要件
分析
- ユーザがどの画面で、どうのような操作をして離脱したかを知りたい
- ユーザがどのくらいの頻度でコア機能を使ってくれているかを知りたい
- ユーザがどんな用途でアプリを使用してくれているかを知りたい
- 細かく定着率を分析したい
- 個人を特定する必要はないがユーザをユニークに扱いたい
- (むしろプライバシーポリシーで約束しているので特定する情報は取らない)
データを活用した施策
- 特定の行動のユーザにのみプッシュ通知で訴求したい
なぜFirebase Analyticsだとだめなのか
イベントログに含めるパラメータのサイズに制限がある
- より詳細な内容を送りたいと思ったときに制限に引っかかり送りきれなかった
ユーザの時系列ログを扱えない
- 特定のユーザがどういうイベント遷移をしたかを追おうとしたときに見るための術がない
- イベント遷移を時系列順にみることができない
- (一応StreamViewで直近アプリを開いていた人だけ見ることはできるがランダムでこちらで選択することはできない)
詳細なセグメントわけをしてユーザを抽出することができない
- 1週間以内にインストールし、コア機能をまだ使っていないユーザ、といった抽出するのがかなり困難
リテンションが見づらい
- リテンションも見ることができるのだが、細かくみたりこちらの定義する「リテンション」で指標を追うことができない
ダッシュボードの読み込みが遅い
以上の理由により、Firebase Analyticsだと困難だったので自前で用意するようにした。
アーキテクチャ

極めて簡単で、アプリでイベントが発生するとFirestoreにログの内容が記録され、 ためていったログデータはCloud Functionによって日時バッチとしてBigQueryに連携される。
実装について
ログのバッファリング
ログを送る処理はイベント発生ごとに送ってしまうと、 無駄に端末リソースを食ってユーザ体験を損ねることになったり、 無駄にアクセスが頻発してしまうので、 バッファリングが必要になる。 そこで、Cookpad社製のPureeを使った。 これは、一定時間もしくは一定サイズのログがバッファされると非同期でログを送ってくれるライブラリだ。 ログの送り先も自分でインターフェースを実装するだけで変えられるので導入が簡単だった。
Firestoreの設計
コレクション定義は下記のようになっている
- users
- evens
userコレクションを作りユーザIDにはFirebaseのInstanceIDを割り当てて、サブコレクションとしてイベントを定義してあげている。 イベントは同時に大量に書き込みが発生するので、コレクションに対する同時書き込み制限に引っかからないようユーザごとにコレクションを分離してあげる形をとっている。 集計するときもeventsで、collection group queryを使えばサブコレクション横断でデータを引っ張って来られるので楽だ。
プッシュ通知
プッシュに関しては、BigQueryで訴求したいユーザ一覧を取得し、CSVをGCSにアップロードすることでPub/SubでトリガーされたCloudFunctionで飛ばすようにしている。 ここは若干面倒なのでうまいことできないか模索している。
やってみてどうか
実際にBigQueryに連携することでかなり細かい条件でユーザを抽出し、訴求することができるようになった。 また、特定のユーザの行動ログも簡単に追うことができ、ここで困ってるんだろうな、、、というのがかなり可視化されてきた。 BigQueryのRECORD型も優秀で、これをしっかり定義してあげれば特にダッシュボードなど用意しなくても見やすくデータが追えるのが良い。DAUやリテンションなど日次で追いたいような指標はデータポータルでダッシュボードを作ることで簡単に閲覧できるようにしている。
気になる料金も、
Firestore
- 読み込み 50000回/dayまで無料
- 書き込み 20000回/dayまで無料
BigQuery
- ストレージ 10GB/monthまで無料
- 処理されるクエリデータ 10TB/monthまで無料
なので、特に無料の範囲で運用できている。 ※一応一定額の課金が発生したらアラートを飛ばすようGCP側で設定している。
まとめ
ツールを使うと、データの扱い方もツールに振り回されてしまうので、ときには自前で実装することも必要になるが、 FirebaseやGCPが充実してきたことでかなり簡単に、少ない工数でやりたいことが実現することができた。 まだ運用上課題はあるので様子をみつつ改善していく。
Stackdriver Monitoringを用いたシステム監視
記事で書くこと
Stackdriver Monitoringを用いたシステム監視を行う方法をまとめる。 特にStackdriver Monitoringはドキュメントからすぐに汲み取ることが難しい部分があるので実際に動かして検証した結果を記載する。
※下記弊ブログのやきまわし Stackdriver Monitoringを用いたシステム監視
Stackdriver Monitoringについて
Stackdriver Monitoringは、GCP、AWSなどのリソースに対してパフォーマンスやリソース状況などのメトリクスを収集して適宜アラート通知をしたりできるプロダクト。 クラウド上のあらゆるリソースに対して特に何もしなくても無設定でメトリクス収集ができるので導入が楽だ。 ただ、実際に特定の条件でアラートを発行するといったことを実現しようとすると多少複雑な概念が絡んでくるので本記事ではそこを整理する。
Monitoringのアラートの基本的な考え方
基本的にはGAEなどのリソースからは特に何もしなくてもCPU使用率やメモリ使用量、コネクション数などのメトリクスがデフォルトで取得できる。 これらの情報は時系列データとして扱われ、このデータを使って条件を設定することでアラートを飛ばすことができる。 アラートは、この時系列データに対して前処理を行い、その結果生成される新たに生成される時系列データをもとに、指定した条件にヒットする場合にインシデントチケット(GitHubのissue、Redmineのチケットのようなもの)が切られてアラートが飛ぶ、という仕組みだ。 そして注意しなくてはならないのが、アラートの通知はこのインシデントチケットに対して飛ぶことになり、Resolveになるまでは新たに通知が飛ぶことはない。 実際に条件を設定するにあたり、あるリソースのある指標の時系列データに対して行える前処理は下記の4つが基本となる。
- Filter
- Align
- Group By
- Aggregate
Filterはそのままで、たとえばHTTPのステータスコードが500であるレコードといった指定になるが、2~4については少しわかりにくいので図解する。
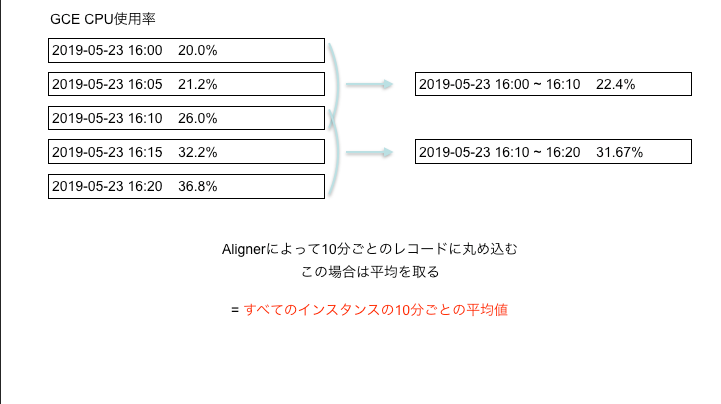
Align
これは時系列に並んだデータに対して、指定した時間ごとに、指定した方法で丸め込むものである。たとえばCPU使用率のデータが5分間隔で取得されていた場合、Alignで10分間隔でその平均をとるようにすると図のようになる。

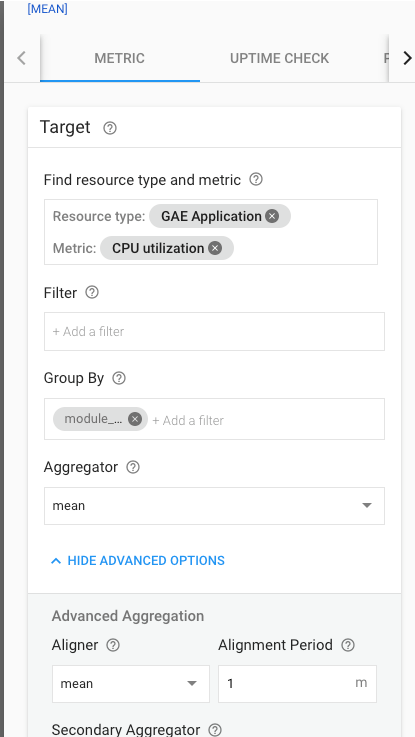
GroupBy + Aggregate
GroupByはSQLでよくある構文と同じ概念として認識すれば良い。 GAEなら各モジュールごと、GCEならインスタンスごとといったように特定のグループで分けて考えることができる。そしてそれぞれのグループに対してAggregateの指定で集計を行う。 例えば図だと、GCEの各インスタンスごとの平均のCPU使用率を集計している。 GroupByで何でグルーピングするか、Aggregateでグループについて何で集計するか(平均を取るのか、合計を取るのか微分するのか等)を指定する。 また、Aggregateはグルーピングしない場合は全体に対して影響する。

こうして、前処理を行うと最終的な成果物として新たな時系列データが生成される。この時系列データに対してインシデントを発行するかの判断をしていて、GroupByによってグルーピングされたものはについてはそれぞれのグループごとに インシデントを発行するかを判別される。よって、それぞれのロケーションごとに別々にインシデント(アラート通知)を扱いたい場合は、GroupByで区切る必要があり、逆に全ロケーションのインスタンスの平均だけとれればいい場合はGroupByせずにAggregatorで平均での集計だけ指定すれば良いということになる。
しきい値
そして最後に一定期間内のしきい値を設定する。 これは前処理の結果によって単位が変わる部分で、例えばCPU使用率なら%だし、 500エラーの数なら何回起こるかを指定する。
サンプル
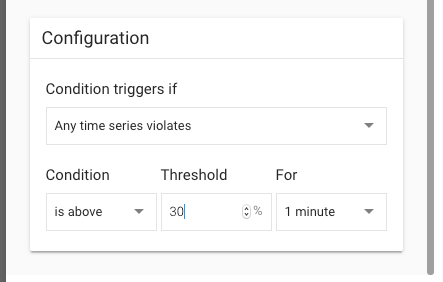
最後にサンプルを示す。 GAEにて各モジュールごとに、10分間の間、1分あたりの平均CPU使用率が30%を超えている場合にアラートを出す、といったルールをどう表現するかというと下記の写真のようになる。
おまけ
レイテンシのチェックや、URL監視を行いたいケースもあると思うが、それはUptimeCheckという機能を使うことで実現することができる。 定期的に世界中各地のロケーションに分散配備されたCheckerプロセスが、指定した期間ごとにリクエストを飛ばしてチェックを行ってくれる。
まとめ
Monitoringは実際に触って動かさないと理解できない部分が多いが、一度慣れてしまうとアプリケーション側をいじらずに簡単に導入ができるので良い感じだった。 ただMonitoringはあくまでもリソースやパフォーマンス、プロセス監視的な意味合いで、アプリケーションのエラーを扱いたい場合にはErrorReportingを使うことになる。 ただこれはSlack通知がGmailの転送とSlack連携を駆使しないとできなかったりして使い勝手が悪いのでGAになったときにどうなるか期待したい。
フルリモートメインのフリーランスエンジニアの活動記録 ~2019-05~
記事について
フリーランスとして開業し、 フルリモートメインで仕事を行ってきて7ヶ月ほど経過したので振り返りを行い、 何を考えて仕事を選択し、どんな学びを得てきたかを整理する。 これからフリーランスになる人や、フルリモートでフリーランスって実際どうなの? って人の役に立てると嬉しい。
どんなことをしてきたか
バックエンドのエンジニアとして、
- GKEによるバッチの開発
- GCPの環境構築の自動化(terraform)
- GAE/Go+firestore+GKE on ElasticsearchによるCMSの開発
- GAE/Go+CloudSQLによるコンシューマ向けWebサービス開発
といったGCPメインでインフラ構築、システム開発に取り組んできた。 基本的には自宅でSlack、HangOut、GitHub、JIRAなどのツールを用いてコミュニケーションを取り、 仕事をしてきた。
契約について
最初こそ請負で受けていたが、今は準委任契約がメインになっている。 毎月安定してお金が入ってくるという安心感と、継続的にチームで開発できるのがメリットである。 特に後者はかなり大きいメリットだ。 フリーランスは技術力が商品になるのだが、一人でもくもくとやっていても限界がある。 優秀な人から学べることはとても多く、新しい視点を与えてくれため自分の能力を効率よく高められる。
どこから仕事を得ているの?
基本直接営業していて、知り合いのツテで紹介してもらった会社にアポを取るか、 wantedlyで気になる会社、スカウトしてきた興味のある会社にたいしてとにかくメッセージを飛ばす、 といったことをして案件を獲得している。
エージェントも最初は検討していたが、
- エージェントよりも自分のほうが、自分が受けたい案件の要件、自身の売出し方についてくわしい
- 案件単価が安い
- フルリモート案件が全然ない
といった理由で使うのをやめた。 これに対しwantedlyは正社員向けのサービスかと思われるかも知れないが業務委託の募集も多く、 フルリモートの交渉も結構通ることが多かったので現在はメインで活用している。 また、エージェントの案件はフルリモートだと単価を安めに設定されることが多いが、 wantedly経由で直接フルリモートの交渉をした場合は今の所希望どおりの単価で通っている。
仕事の選択方針は?
3つあって、
- 単価が自分の希望に沿っているか
- リモート可能か(最悪フルでリモートでなくても良い)
- バックエンドエンジニアとして専門性を高められそうか
これらの基準で選んでいる。 上2つは省略するが、3つ目について少し説明する。
バックエンドとして専門性を高めるということ
前提としてフリーランスとしてやっていくのにフルスタックエンジニアはおすすめできない。 なぜなら、大抵の案件はバックエンド、フロントエンドといった棲み分けがされた状態で募集がされていて、 幅広くできても個々の深さが足りてないと高単価は狙いにくいからだ。 たまに全部ものすごい深さでできるスーパーエンジニアがいるが、自分のような凡才にはムリだ。 よってスキルを選択してフォーカスすることが重要になる。
では、バックエンドにフォーカスしたときに他者と差別化していくためにはどうしたら良いだろうか? ただ単にAPIの開発ができてDBにアクセスしてデータとってきて返せます、 だとこれから大量に流入してくるだろう初心者エンジニアと差別化が大してできない。 ポイントとなるのは、 「インフラ、ソフトウェアのレイヤーにそれぞれにおいて、与えられる要件に対して適切な設計、運用ができる」 ということだと考えた。 もちろん完璧な設計をするのはムリなので、ここでいう適切とは、
機能要件、非機能要件を満たすことができ、 ある程度のアジリティでエンハンスしていくことのできるシステムを作れるか
という基準だと考えている。 よって、
- サービスに求められる非機能要求やSLAのレベルが何かしら高い
- 高負荷
- 大規模データ
- 要件が特殊
といったようなプロダクトで経験をつもうと考え、選択している。
フルリモートをやっていて気をつけていること、大事なこと
基本的にここでいっていることと同じだ。
進捗、着手状況を常に見える化し、仕事のゴールと方針のすり合わせ、複雑なタスクは細かくレビューをもらって手戻りを防ぐ、 といったことを実践している。
フルリモートで良かったこと
自分はかなり内向的な性格で、日常会話レベルでも周りの目をどうしても気にしてしまい、 その場では言いたいことを言えなかったりする。 だが、家にいて非同期コミュニケーション中心の場合は整理してから伝えられるので、 言いたいことをはっきり言えてとても気が楽だ。 また、やはり人と対面するとエネルギーを消費するので(嫌いなわけじゃなく、性質の話)、 仕事以外の理由で疲れにくいというのは大きい。 これのおかげで朝勉強し、ジムに言ってから仕事をして、仕事後は個人開発、というリズムをあまりくずさずに実施できている。 独立する前、毎日会社に通っていた頃は常に息切れ状態で他のことをする余裕なんてまったくなかった。
フルリモートで良くなかったこと
フルリモート前提でプロセスが組まれていない限りどうしても気をつかわせてしまう
会議中にリモートの自分に配慮して、 Jamboardといった通話相手にもホワイトボードに書いたことを共有できるようなツールを使ってくれたり、 はっきり聞こえるように大きな声でゆっくり喋ってくれる人がいたりする。 ちょっと申し訳ない。
情報から隔離される
自分が知らない間に設計とか方針とかが会社で決まってしまうことがあり、プロジェクト全体を見通しにくい。 全体が見通せないと、ただの作業する歯車になってしまい、主体性を保ちにくくなってしまう。 なるべくissueやSlackのログや議事録を読んだり、オンラインでの議論に参加することで保っている状態。
まとめ
リモートメインでの活動は良い面だけでなくどうしても課題はある。 ただ、仕事を得られないとか、自分がしたいことができないといったことは幸いなく、 実際の開発プロセスでの課題に終始していることが救いだった。 リモート開発のメインの課題は情報の共有なので、うまくまわってるところはどういうふうにまわしているのかきいてみたい。
開発生産性を高めるアーキテクチャの本質 ~Clean Architectureを読んで~
どんな記事を書くか?
「Clean Architecture 達人に学ぶソフトウェアの構造と設計」という本を読み終えた。 非常に勉強になる本だったので、自分なりの解釈をしつつ学んだことをまとめる。 ※私個人の解釈を存分に含んでいる アーキテクチャは何のために設計するものか? ソフトウェアのアーキテクチャは何のためにあるものだろうか? 本書では「開発にかかる人員を最小にするものである」と述べてられている。 アーキテクチャが整備されていないプロダクトはどうなるかというと、 一つのクラス、レイヤが責務を抱え過ぎたり、修正、変更のスコープが必要以上に広がっていってしまうことになる。 FatなActivityやViewController、DB周りの変更が他の層に影響を及ぼすなどがその最たる例だ。 そして汚い設計のプロダクトは、時を経るごとにより汚いものにどんどん変貌していく。 アーキテクチャがイケていないと負債を増加させ、プロダクトが価値を生むまでのリードタイムをどんどん延ばしていってしまう。
開発スピードを遅くする条件とは?
では、システムのアーキテクチャ設計において開発スピードを遅くする条件とはどんなものがあるだろうか? それは主に2つあると考えられる。 - 早すぎる決定による設計の汚染 - 実装の詳細がビジネスロジックを汚染している
である。 順に説明する。
早すぎる決定による設計の汚染
決定を下すのはなるべくそのための知見が集まってから下すのが一番良い。 そうすることで決定の質を高め、将来的なムダな手戻りや運用開発コストを削減できることができる可能性が高まる。 例えば新規にシステムを開発するとき、使用するデータストアはどのタイミングで決めるだろうか? たいていの場合、設計フェーズの割と初期で決めることが多くないだろうか? ひどい場合だと要件定義の段階ですでに固定されているケースもある。 これは何を引き起こすだろうか? 開発の早いタイミングでMySQLを採用すると決め、その前提で開発をすすめていたものの、 システムの仕様への理解が進むにつれ、実は単純なファイルの読み書きで済んでしまうことがわかったとする。 だが開発はもうMySQL前提で実装されていて、大幅な手戻りになってしまうためこのまま進むことになってしまった。 そうすると下記のような開発、運用コストを余分に生み出してしまう。 - テーブル設計などRDBならではの余分な設計と実装コスト - リリース後のMySQLサーバの運用
このように「早すぎる決定」によって不必要なコストを長期的な未来に渡って抱え込むことになってしまう。
実装の詳細がビジネスロジックを汚染している
ビジネスロジックを記述しているクラスにWebやDBなどの「実装の詳細」を記載してしまうことで、 クラスの変更理由をビジネスロジックの変更以外にかかえてしまう。 つまりクラスの変更理由が複数になってしまう。 これはSOLID原則のS、単一責任の原則に違反している。 こうした違反が、将来的な修正、機能追加のコストを増大させてしまう。
良いアーキテクチャの本質
ではどのように設計してこれらの問題を解決していけばいいのか。 その本質は下記の図のような設計だ。

ドメイン、つまり業務知識とそれ以外をまずわけて考えるということだ。 システムにおいてまず最初に決まり、そして変わらないものはなにか? それはビジネスロジックだ。 ビジネスロジックを起点と考え、Web、データストア周りの実装をそこに付随するその他の関心事としてとらえる。 そして、ビジネスロジックは何にも依存せず、逆にその他がビジネスロジックに依存する仕組みにする。 こうすることで、ビジネスロジック以外は「プラグイン」に過ぎず、ビジネスロジックはそれ以外のものの影響を受けなくなる。 これが全てに通ずる良い設計の本質である。 ヘキサゴナルアーキテクチャ、オニオンアーキテクチャ、クリーンアーキテクチャなど種類が様々にあるが、本質はどれも一緒のはずだ。
クリーンアーキテクチャ
上述した本質をもとに、より現実的なレイヤーに分かれているアーキテクチャの一つがClean Architectureである。

Use Case層とEntitiesがビジネスロジック部分になる。 Entitiesに振る舞いを記述し、Use Case層でそれらを制御していく。Controllers、Gateways、PresentersはUse Caseからの入出力をWebやDB、UIなどが解釈できる構造に変換してあげる役割がある。
そしてこの同心円で一番大事なのは依存の方向である。
ビジネスロジックは何にも依存しない。その他の関心事がそれらに依存する形になる。 こうすることで出力先がWebになろうが、コンソールになろうがビジネスロジックは一切の影響を受けない。 データストアについてもしかりである。
一般的な3層アーキテクチャから来た人はデータストア側がビジネスロジックに依存する、というところに違和感を覚えるかもしれない。
よくある構成だと、Controllers(WebのIF) -> Service(ビジネスロジック) -> Repository(データアクセス)となっていて、ビジネスロジックがデータアクセス層を使って処理を構築するような仕組みになっているからだ。

だが、このような依存の方向にしてしまうとデータアクセスがビジネスロジックに影響を与えてしまう。 これではビジネスロジックは守られない。 ここで「依存性逆転の原則」を適用し、ビジネスロジック側でほしいデータアクセス処理のインターフェースを定義し、ビジネスロジックはインターフェースに対してアクセスする。 そしてデータアクセス層が、ビジネスロジックで定義したインターフェースを実装するという形にする。 これによって、データアクセス層がビジネスロジックに依存する形にでき、ビジネスロジックを独立させることができるのだ。
このように、ビジネスロジックとそれ以外の間にインターフェースで「境界」を作り、依存関係を制御してビジネスロジックを守るようなアーキテクチャになっている。

クリーンアーキテクチャで結局何が嬉しい?
こうしたアーキテクチャは何が嬉しいだろうか? それは下記になる。 決定を遅らせることができる 責務の切り分けが明確になる テストが容易になる
クリーンアーキテクチャを適用することで、ビジネスロジックから実装し、データアクセス層など他の層はスタブとして実装を進められる。つまりある程度実装を進め、ビジネスロジックへの知識が増えてから適切にデータストアや入出力(WebとかUI)の詳細を決定することができる。 これは「リーンソフトウェア開発」の決定を遅らせるという原則に則している。これにより、将来的なムダを削減し、ソフトウェアが価値を生むまでのリードタイムを短縮できる。 そして責務が明確になることで特定クラスの肥大化、変更スコープの肥大化を防ぐことができ、レイヤーが独立していることでテストのハードルが下がる。 ただ、これらのメリットの重要性はプロダクトがどのフェーズにいるかによって変わってくるだろう。 例えば新規開発時には、クリーンアーキテクチャは、責務の切り分けという観点では大げさに思えるかもしれない。 だが、決定を遅らせることができる、という点では多くの利点がある。逆にリリースしてエンハンスのフェーズに入ると、決定を遅らせることによるメリットを明確に感じる機会はそんなに多くないかもしれないが、責務が別れていてテストがしやすいことにより、負債を抱えて開発スピードを落とすことなく安定してグロースしていける可能性が高まる。
まとめ
アーキテクチャ設計もより視座を上げてみればプロダクトが価値を生むリードタイム削減に寄与する重要な要素である。 変わらないものであるビジネスロジックを依存関係から解放し、他をそこに付随するプラグインとしてあげることで「決定を遅らせ」、ムダな疲弊をへらす事ができる。 クリーンアーキテクチャではないアーキテクチャを採用したとしても、この本質は変わらないはずなので常に意識しておきたい。
【保存版】4年間現場で培ったプロダクト開発を支えるエンジニアリング
何を何のために書くのか
プロダクト開発を行うエンジニアチームが、 どんなことを目標にして、 どんな環境を作っていくのかを、 4年間プロダクト開発を行ってきた自分の集大成として一度言語化してまとめたい。 自分が関わった現場では何のためにどんなことが行われていたかの全体感をまとめ、 今後参画する現場の課題の検知、優先度付け、行動指針をぶれないようにする目的でブログ記事化する。 あくまでも全体感を把握するためなので個々について細かく詳細は記述しない。
アジェンダ
- プロダクト開発を行うエンジニアとは?
- プロダクト開発を行うエンジニアチームの存在意義
- プロダクト開発を行うエンジニアチームの存在意義と目指す方向
- フロー上のムダをなくすための環境作り
- 安定してサービス提供するための環境作り
プロダクト開発を行うエンジニアチームとは
ビジネス上の目標を持ち、 世の中になんらかの価値を提供するプロダクトを開発、運用するエンジニアチームを指すこととする。
プロダクト開発を行うエンジニアチームの存在意義と目指す方向
では、エンジニアチームが持つべきミッションは何になるのか? 結論だけ先にいうと下記の2つになる。
- 企画~リリースまでのフロー上のムダをなくしていくこと
- SLA/OLAにコミットし、安定してサービスを提供し続けること
どういうことか? プロダクトの最終ゴールはお金を生み出すことである。 つまり、お金を生み出すまでのフローのムダを解消し、安定して開発、運用することがコアなミッションになる。
企画からリリースまでには、
- 仮説立て
- 企画
- 要件定義
- 設計
- 実装
- テスト
- リリース
- 効果検証
といった工程が存在する。 このフロー上のムダを解消することで、 仮説立て ~ 効果検証までのサイクルを最速にし、 強いプロダクトを生み出すための環境を作ることができる。 そしてこのフロー上のムダは、
- フローのどこかにムダがあるケース
- フローの外部の要因によってフローの進行が妨げられるケース
の2つのパターンがある。 前者は言うまでも無いが、後者については、 例えば障害対応、ユーザからの問い合わせの対応などにあたる。 障害やユーザからの問い合わせが発生すれば価値を生むための開発に充てるための工数が減っていく。 つまり生み出した欠陥によってお金を産まないムダなことをしなくてはならない。 また、障害の内容によっては(個人情報の流出など)サービスの存続すら危うくなってしまう。
だからこそ、
- SLA/OLAにコミットし、安定してサービスを提供し続けること
はとても重要になってくる。
フロー上のムダをなくすための環境作り
ドキュメント整備
開発をしていて得られた技術的な知見、 チーム内で決まった意思決定の議事録、 環境構築の手順、 システム構成図などはチームメンバー間で何度も参照され得るような再現性の高い内容である。 こうした内容を簡単に検索、参照できるように整理しておくことで、 新しいメンバーが入ってきたときにもすぐキャッチアップして立ち上げられ、 一度やった内容なのに資料がないため再調査、といったようなムダを省き、 タスクの属人化の問題を防ぐことができる。 なんでもかんでもドキュメント化しておけばいいわけではないが、 チームで育てた知見を明文化することはとても大切である。
テストコード
ビジネスの状況はどんどん変遷していくので、プロダクトも常にそこに追随していく必要がある。 テストコードがなければ、 EOLになったライブラリのアップデートさえ上げることに苦労し、 リファクタリングが容易にできず、 改修、拡張の結果デグレがおこったとしても人手以外で検知する術がない。 つまり変更が容易にできない。 テストコードを書かないことによって目先の工数は減らせるが、 その後長期に渡って必要のないムダを生みだすことになる。 一回だけ書いて一切拡張、修正せずに運用するソフトウェア以外についてはテストコードは書くべきである。
各種テストの自動化
単体テスト以外にも、プロダクトならではで手間がかかっているテストがあるはずだ。 たとえば課金の仕組みを持つプロダクトで、課金部分は求められるサービスレベルが高いのでいつも厚めにテストをする、 といったことや、会員制のサービスでテスト用のアカウントを毎回人手で作っていて時間がかかっている、などだ。 こういったところの一部でも自動化することができれば、長期にわたる人件費やテスト工数の削減につなげることができる。
継続的インテグレーション
PullRequestを出した時点でビルドし、テストを実行するのはもうどこの現場でもやられているはずだ。 これによってmasterやdevelopなどのメインブランチにビルドが通らなかったりテストが通らないコードを混入させて チームメンバーの作業をブロッキングすることを回避し、バグの混入を早急に検知して手戻りを防ぐことができる。 またCIに静的解析などを含めることで、バグや障害のリスク回避はもちろんPullRequestのレビュワーの負担を軽減することもできる。
継続的デリバリー
PullRequestが通り、develop、masterにマージされたタイミングで(もしくはPullRequestの時点で)ステージングや開発環境に自動的にデプロイすることで、サーバとフロントの結合や、見た目の部分をいち早く確認することができる。 また、常に最新の開発状態のものを確認することができる。 これによって、デプロイ自体の属人化回避や工数削減はもちろん、すぐに確認できることによってバグやあとの工程での手戻りなどを防ぐこともできる。
データ分析基盤
より良いプロダクトを作っていくためには、 仮説を立て、リリースし、フィードバックを得て学びを得て次の仮説を立てる、 といったサイクルを良質に回していく必要がある。 ここがうまく機能しないと、 ユーザに使われないものを多くの金と工数をかけて世に生みだすことになってしまう。 そのためには、
- 各施策で効果振り返りを適切に行えること
- ユーザの傾向分析などを通して新たなニーズの仮説打ち出しができること
が求められる。 1. どんなデータ、ログがあれば適切な効果測定、適切な傾向分析ができるかの要件出し 2. 要件から実際にログ収集、分析のための仕組みづくり を行うことが求められる。
進捗の可視化
進捗管理はとても重要だ。 見えないことによってリリース日までにどのくらいできて、どれをスコープから外すか、といったような判断ができない。 また、見えないとそもそも何に時間がかかっているのか?といった問題が表面に出てこない。
優先順位の可視化
すべて最優先で、というのはすべて優先度低と言っているのと全く同じだ。 リリースしたい機能、タスクの優先度が見える化された状態で直列に並んでいて、 かつ合意が取られていることで納得して開発でき、柔軟なスコープ調整や、技術都合で必須なものの調整(EOL対応など)が健全にできる。
開発プロセスの整備
開発フローの整備
- Gitのブランチ運用ルールの整備や、障害発生時のエスカレーション、対応ルール、開発とテストの工程定義などはチーム内で明文化しておく必要がある。
- これによってフロー上の品質のブレや、いざというときの対応でもたついて対応がスムーズにいかない、といったことを防ぐことができる。
カイゼンのためのチームづくり
安定してサービスを提供し続ける環境作り
静的解析 & 脆弱性チェック & ライブラリEOLチェック
欠陥を未然に防ぐことはとても重要で、これによって最悪サービス提供ができなくなることもある。 また、ライブラリEOLが原因でアプリストア上で公開できなくなったり、障害の発生によって開発フローを妨げられたりする。 脆弱性をついた襲撃を受けたり、個人情報漏洩などのリスクが発生することもある。 よって、常日頃からコードの品質、ライブラリのバージョン、脆弱性についてはチェックしておく必要がある。
クラッシュログモニタリング
Firebase/Crashlyticsなどのアプリのクラッシュログを収集するSDKを入れ、 定常的にモニタリングすることでテストではきがつけなかったバグの混入などを検知する。
サーバ監視&アプリケーションモニタリング
サーバダウンや、リソース使用状況、エラーログや、APIのレスポンスタイムなどを計測することで、 障害の検知や、障害時の原因特定を行うことができる。 またプロダクトの宣伝を大々的にしたときにインフラが耐えられるかや、ユーザ増加にどこまで対応できるかの分析を行い、 インフラ増強や構成の改善に役立てる。
リリースエンジニアリング
大規模な変更などのリスクのあるリリースでも、 安全にリリースを行う仕組みを活用すれば障害時の影響を最小にすることができる。 また、実験的に一部のユーザにだけ機能を見せてフィードバックを得てから本格的に開発を進めるなど、 MVP検証的なことが可能になる。
具体的には下記のような手法がある。
- 段階的リリースで一部のユーザにのみリリースしてフィードバックを得る
- 機能をダークローンチして、実際にユーザに使わせる前に本番環境で内部検証する
- 時限式リリースで、指定した時刻になってはじめて自動的にユーザに見えるようにする 例: 何周年キャンペーンとか
- Feature Toggleを活用してリリース無しで挙動を変える
- タスクキューやメール配信などの流量をリリース無しで動的に制御
- リスクのある機能をToggleでON/OFFできるようにしておき、問題を検知したらすぐOFFにする
まとめ
プロダクト開発におけるエンジニアチームはプロダクトが安定して利益を生み出す仕組みをエンジニアリングすることに責務を持つ。 そのためにムダを省き、安全に安定してサービスを提供する。 ここがブレなければ独りよがりではなく、うまく技術を利用していけるはず。