Stackdriver Monitoringを用いたシステム監視
記事で書くこと
Stackdriver Monitoringを用いたシステム監視を行う方法をまとめる。 特にStackdriver Monitoringはドキュメントからすぐに汲み取ることが難しい部分があるので実際に動かして検証した結果を記載する。
※下記弊ブログのやきまわし Stackdriver Monitoringを用いたシステム監視
Stackdriver Monitoringについて
Stackdriver Monitoringは、GCP、AWSなどのリソースに対してパフォーマンスやリソース状況などのメトリクスを収集して適宜アラート通知をしたりできるプロダクト。 クラウド上のあらゆるリソースに対して特に何もしなくても無設定でメトリクス収集ができるので導入が楽だ。 ただ、実際に特定の条件でアラートを発行するといったことを実現しようとすると多少複雑な概念が絡んでくるので本記事ではそこを整理する。
Monitoringのアラートの基本的な考え方
基本的にはGAEなどのリソースからは特に何もしなくてもCPU使用率やメモリ使用量、コネクション数などのメトリクスがデフォルトで取得できる。 これらの情報は時系列データとして扱われ、このデータを使って条件を設定することでアラートを飛ばすことができる。 アラートは、この時系列データに対して前処理を行い、その結果生成される新たに生成される時系列データをもとに、指定した条件にヒットする場合にインシデントチケット(GitHubのissue、Redmineのチケットのようなもの)が切られてアラートが飛ぶ、という仕組みだ。 そして注意しなくてはならないのが、アラートの通知はこのインシデントチケットに対して飛ぶことになり、Resolveになるまでは新たに通知が飛ぶことはない。 実際に条件を設定するにあたり、あるリソースのある指標の時系列データに対して行える前処理は下記の4つが基本となる。
- Filter
- Align
- Group By
- Aggregate
Filterはそのままで、たとえばHTTPのステータスコードが500であるレコードといった指定になるが、2~4については少しわかりにくいので図解する。
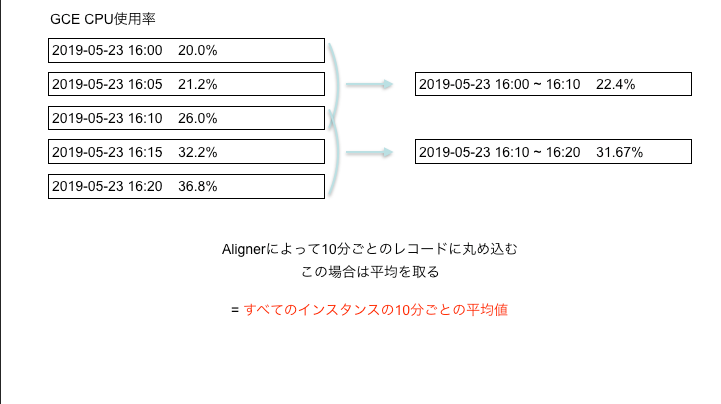
Align
これは時系列に並んだデータに対して、指定した時間ごとに、指定した方法で丸め込むものである。たとえばCPU使用率のデータが5分間隔で取得されていた場合、Alignで10分間隔でその平均をとるようにすると図のようになる。

GroupBy + Aggregate
GroupByはSQLでよくある構文と同じ概念として認識すれば良い。 GAEなら各モジュールごと、GCEならインスタンスごとといったように特定のグループで分けて考えることができる。そしてそれぞれのグループに対してAggregateの指定で集計を行う。 例えば図だと、GCEの各インスタンスごとの平均のCPU使用率を集計している。 GroupByで何でグルーピングするか、Aggregateでグループについて何で集計するか(平均を取るのか、合計を取るのか微分するのか等)を指定する。 また、Aggregateはグルーピングしない場合は全体に対して影響する。

こうして、前処理を行うと最終的な成果物として新たな時系列データが生成される。この時系列データに対してインシデントを発行するかの判断をしていて、GroupByによってグルーピングされたものはについてはそれぞれのグループごとに インシデントを発行するかを判別される。よって、それぞれのロケーションごとに別々にインシデント(アラート通知)を扱いたい場合は、GroupByで区切る必要があり、逆に全ロケーションのインスタンスの平均だけとれればいい場合はGroupByせずにAggregatorで平均での集計だけ指定すれば良いということになる。
しきい値
そして最後に一定期間内のしきい値を設定する。 これは前処理の結果によって単位が変わる部分で、例えばCPU使用率なら%だし、 500エラーの数なら何回起こるかを指定する。
サンプル
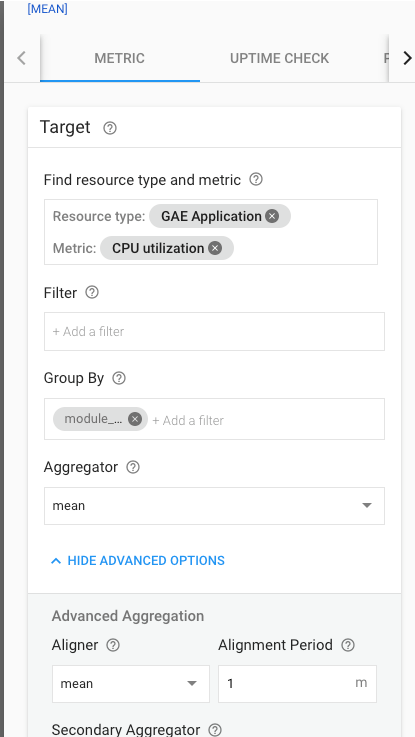
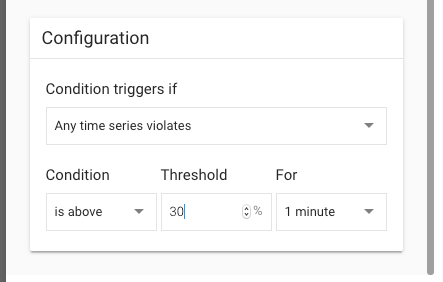
最後にサンプルを示す。 GAEにて各モジュールごとに、10分間の間、1分あたりの平均CPU使用率が30%を超えている場合にアラートを出す、といったルールをどう表現するかというと下記の写真のようになる。
おまけ
レイテンシのチェックや、URL監視を行いたいケースもあると思うが、それはUptimeCheckという機能を使うことで実現することができる。 定期的に世界中各地のロケーションに分散配備されたCheckerプロセスが、指定した期間ごとにリクエストを飛ばしてチェックを行ってくれる。
まとめ
Monitoringは実際に触って動かさないと理解できない部分が多いが、一度慣れてしまうとアプリケーション側をいじらずに簡単に導入ができるので良い感じだった。 ただMonitoringはあくまでもリソースやパフォーマンス、プロセス監視的な意味合いで、アプリケーションのエラーを扱いたい場合にはErrorReportingを使うことになる。 ただこれはSlack通知がGmailの転送とSlack連携を駆使しないとできなかったりして使い勝手が悪いのでGAになったときにどうなるか期待したい。