2020年の振り返りと今後の展望
本記事について
今年ももう終わるので今年やったこと、考えたことを振り返り、来年につなげようと思います。 また今年で一旦フリーランス辞めて会社員に戻るつもりなので、何を考えてその決断をとったのかを整理しておきます。
今年注力した技術
- Kubernetes
- Istio
- ArgoCD
- GCP Anthos
- Anthos Service Mesh
- Ingress For Anthos
今年やった仕事
アウトプット
登壇
本
ブログ
OSS
- Chord Protocolの実装
- Multi Clusterのバージョン管理のためのCustom Controllerの開発
- ArgoCDへのContribute
- GitOpsEngineへのContribute
振り返り
良い点
今年は相当アウトプットを頑張った年になりました。 登壇、有名OSSへのContributeに加え、 zennで書いた本や、qiitaに上げたKubernetesの記事がうまいことバズリ、 多くの人に自分のアウトプットを見ていただくことができました。
また、仕事に関してもお世話になった某メディア会社では、 フリーランスの自分に、技術検証、選定、実装&リリース、運用と運用整備まで一貫して主導でやらせていただけて、 大きな成長を感じると共にとても楽しく働くことができました。
反省点
大規模サービスになってくると、扱う技術の制約はより重要になってきます。 管理できるノード数であったりクラスタ数、リクエスト数、コストなどの制約は、 技術選定のための検証時にしっかり限界まで見て測っておかないと、 後々の工程で大幅な手戻りをすることがあります。 リアーキテクトに携わる中でこれを身を持って痛感しました。
フリーランスをやめる理由
今後エンジニア市場により若い人たちがどんどん参入していく中で、 何十年後も一定以上の収入を維持しつづけることを目標にしたときに、 フリーランスだとそれに必要な経験を積んでいくことが難しいなという結論にいたりました。
というのも今後は、
- 技術はどんどんコモディティ化し、単体の技術を扱って何かを作る障壁はどんどん下がってくる
- エンジニアの需要増加、待遇向上につられてエンジニアの数自体はどんどん増えていく
ということが起こるのかなと考えています。 小学生でも優秀層はWebRTCなどを駆使してプロダクトを作れる時代の中、 すぐにキャッチアップできるスキルをいくら身につけてもすぐ追いつかれてしまうので、 経験を積むことで差別化できるような知見、スキルを得ていく必要があるなと感じてます。
そのために、
- 幅広く技術やそのメリデメを熟知していて、要件に対して最適に選択でき、運用設計まで行える
- 難易度の高い要件にもしっかり対応することができる
- ある特定分野で業界をリードできるだけのスキルとブランディングを築いていく
このへんのポイントをキャリアに加えていくことを重点的にキャリア形成を考えています。 しかし、フリーランスではそもそも意思決定に関わる機会がどうしても減ってしまいます。 要件が難しくなる大規模環境では特にフリーランスへの情報開示、権限などがある程度制限されることが多いです。 そうなると、要件の落とし込みから導入、運用設計まで裁量を持ってやることのハードルが高くなってきてしまい、 良質な経験値を積めるかどうかは運次第になってきます。
よって、一旦会社員になろうと決意しました。
次はどこに行くのか?
LINE株式会社でプライベートクラウドプラットフォームを開発、運用する部署に行きます。 人生で一度はクラウドづくりしてみたかったのでとても楽しみです。
マルチクラスタKubernetes 3つのパターンと実運用事例
この記事はKubernetes Advent Calendarの7日目の記事です。 今回は、Kubernetesのマルチクラスタ化についての考察記事を書きます。
マルチクラスタの定義
マルチクラスタと一重にいっても色々とありますが、本記事では、「複数のKubernetesクラスタを並列に並べ、トラフィックを特定の条件でそれぞれにルーティングする」構成のことを指すとします。
また常時マルチクラスタではなく、普段はシングルでも、いつでもクラスタを並列に並べることができる構成もマルチクラスタ構成とします。

マルチクラスタが必要になるケース
運用する側としては、クラスタの数は少なければ少ないほど嬉しいはずです。
では、どのようなケースでマルチクラスタ構成を取る必要が出てくるのでしょうか?
Multi-cluster use casesにも記載されていますが、コアなものに絞って要約すると、下記のようになると解釈しています。
可用性の向上
地理分散への考慮
- リクエスト元のロケーションを考慮したルーティング
- Locationごとの固有サービスのデプロイ
セキュリティポリシーへの対応
- 特別セキュリティが厳しいワークロードとそうでないものを区別して、別々のクラスタで運用
パフォーマンス改善
- master nodeを分離することでクラスタ機能そのものの負荷を分散
私の現場のケースで採用に至った理由
私のケースでは「可用性の向上」が主たる理由になります。
Surge Upgrade + Graceful Shutdownを有効にしているものの、Master Upgradeしただけでも一瞬ダウンタイムが挟まってしまっている(原因究明中)
アップグレード起因で何か問題があったとしてもFail Over、ないしロールバックはできるようにしておきたい
BCP観点でリージョン障害に耐えうる構成を取る必要性
これらがマルチクラスタで実現したかった要件になります。
マルチクラスタの実現方法
では、この要件を満たすためにどうすればマルチクラスタ化を実現できるでしょうか?
主に一般的なのはこの3つではないでしょうか。
- DNSパターン
- HA Proxyパターン
- Global Load Balancerパターン
1. DNSパターン
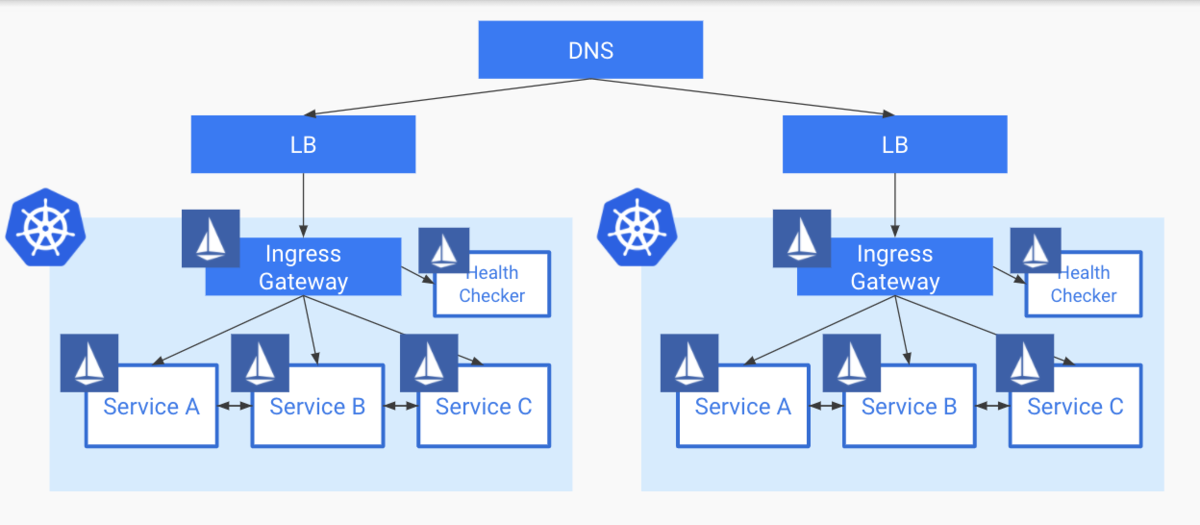
これは一番シンプルで運用が楽なパターンではないでしょうか? これはクラスタを指すドメインに対して、複数のクラスタのIPを登録しておく構成になります。 クラスタのIPはNodePortもしくは、L4ないし、L7のLBを払い出すことになります。
メリット
- シンプルで管理運用コストが低い
- Route53などを使えばGeographic Routingも可能
デメリット
私のケースでは特にこのTTLの部分で、即時FailOverできない点、ロールバックなどが気軽に行えい点を踏まえてこのパターンは見送りました。
2. HA Proxy パターン
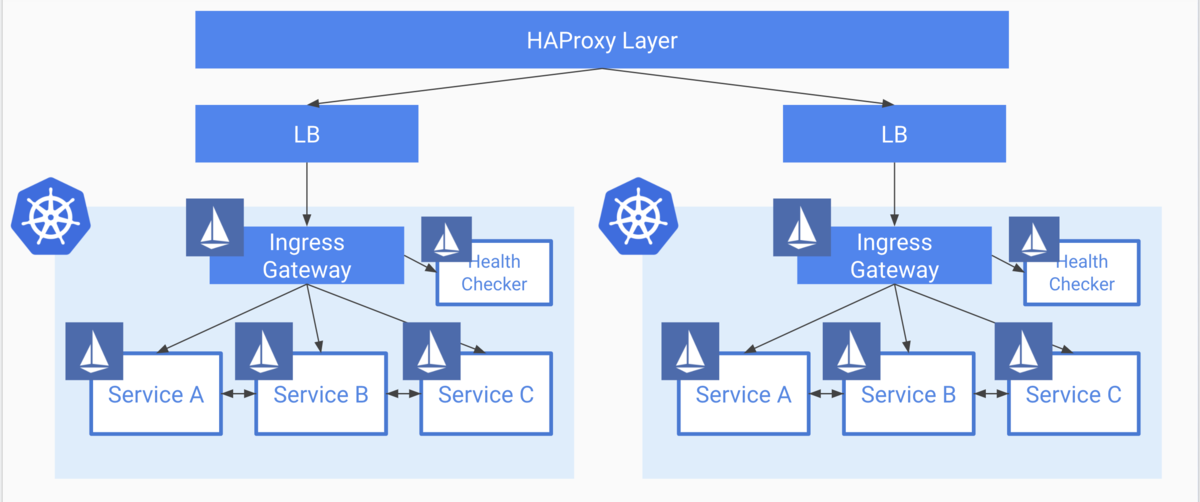
このパターンは、前段にHAProxyのクラスタを設置し、そのバックエンドとしてKubernetesクラスタを置くパターンです。 HA Proxy自体を冗長化しておくために、何台かを並列で並べて管理する必要があります。
可用性の文脈ではなく、各コンポーネントごとに配置するクラスタを分散して、そのためのトラフィック制御を行う文脈ですが、コロプラさんがこの構成をとっています。
メリット
デメリット
- Managedなものを使わない限り、HA ProxyがSPOFにならないよう管理運用コストがかかる
このパターンもメリットは大きいものの、HA Proxy自体の可用性、耐障害性への管理運用コストを鑑みて見送りました。
3. Global Load Balancerパターン
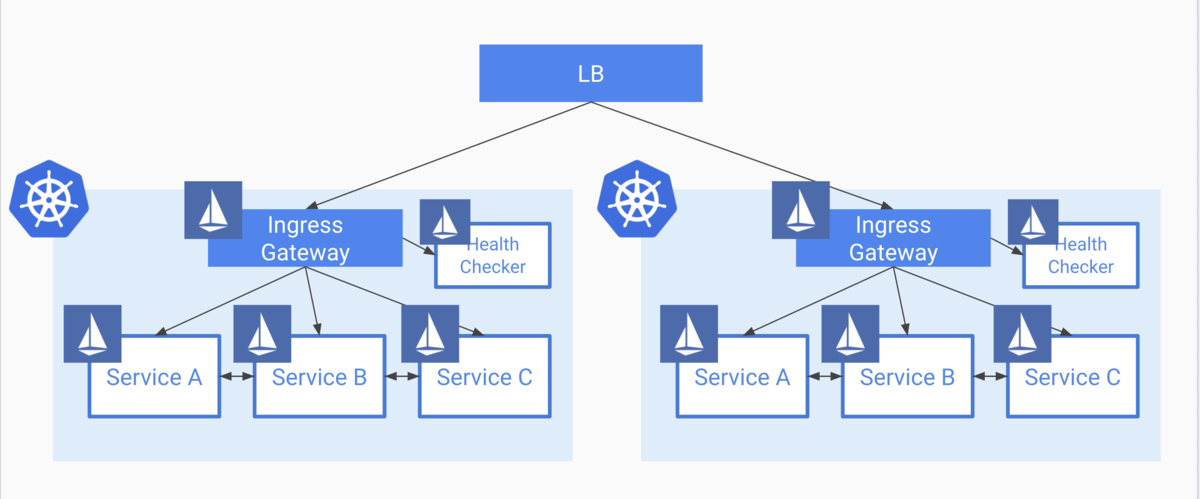
これは、クラスタの前段にグローバルなLBを配置し、その下にクラスタを置くパターンです。 私のケースでは、前述2パターンのデメリットが許容できず、消去法でこのパターンになっています。
LBそのものの機能性に左右されそうですが、 このパターン自体のメリデメは下記のようになっています。
メリット
- LBからのヘルスチェック機構により、即時でFail Overできる
- TTLなどに支配されない
- 管理運用コストが比較的低め
デメリット
- HAProxyのような細かいトラフィックルーティングができない ※1
- 各ゾーンごとに均等に分散されるだけ
- HAProxyのような細かいトラフィックルーティングができない ※1
※1 AWSでEKSを使えばできる模様
ALB Weighted Target Groups による EKS Cluster の Canary Switching
Global Load Balancerパターンでの実運用
前述した通り、最終的にはLoadBalancerパターンを用いて対応しました。 このパターンを実現するために、GCPのIngress For Anthosの機能を使って実現しており、構成の詳細について、Kubernetes MeetUp Tokyoにて私がLTした資料に記載してあります。
Ingress For Anthosを活用した安全なk8sクラスタ運用
Ingress For Anthosを使うことで、LBの設定は完全に自動化されています。 これにより、
といったことが担保できています。
この構成での惜しいところ
消去法で選んでいるので、当然完璧ではありません。 少なからず辛いところは存在しています。 例えば下記のようなポイントです。
Config ClusterというLBの設定同期用のクラスタを用意し、そこにLBの設定をデプロイしなくてはならない
マルチクラウドが実現できることにはできるが、EKSをそのまま突っ込んだりできるわけではなく、それなりに複雑な構成を取る必要がある
実際のクラスタアップグレードについて
実際のアップグレードとしては、
といったようにローリングアップデートの形をとっています。
ただ、カナリアリリースのようなことはできないので、 いきなりクラスタをサービスアウトし、アップグレードするようなことをやると、一気にトラフィックが片側に流れることになってしまいます。
現在は、ある程度minimumのPod数をある程度積んでおくことで対処していますが、これはリソース効率が悪く、本意ではありません。
よって将来的には、
といった対応をする必要が出てくる可能性があります。
(現在はコスト面でもトラフィック面でもゆとりがあるので予定はありません)
マルチクラスタとGitOps
これは余談ですがマルチクラスタ化するにあたり、GitOpsの考え方を取り入れて、ArgoCDによってデプロイパイプラインを組んでいたことにより、ここに関してはほぼノーコストで移行できました。 また、移行後も特に問題なく稼働できています。
ただ、現状各クラスタごとにArgoCDを独立してデプロイしており、各クラスタの状態を見るためには各クラスタ用のダッシュボードをみる必要があります。
一応ArgoCD側でもMultiClusterのための提案がなされていて、一つのApplicationに対して複数クラスタへのデプロイができるような、ApplicationSetというCRDおよびOperatorの開発が進んでいるようです。
まとめ
本記事ではマルチクラスタ化する理由、実運用してみた所感について紹介してきました。 Kubernetesを安全に運用するためのエコシステムはどんどん様々なソリューションが生まれてきており、今後も益々発展していくと思いますが、本記事が何かのお役に立てれば幸いです。
k8sを運用するなら絶対抑えておきたい、可用性とScalabilityを担保するための大事な観点
概要
先日、Kubernetes Novice Tokyoというイベントで「k8sのAvailabilityとScalabilityを担保するための大事な観点」というタイトルで登壇させていただきました。 運用する上で気にするべき、可用性とスケーラビリティに関する基本的な内容を、 今後のプロジェクトで振り返って参照できるよう体系的にまとめて資料にしています。
内容
スライドはこちら。
まとめ
今後もk8sを本番で運用する上で得られた知見を積極的に発信していく予定です。
Kubernetesの負荷試験で絶対に担保したい13のチェックリスト
概要
ここ最近、Kubernetesクラスタを本番運用するにあたって負荷試験を行ってきました。
Kubernetesクラスタに乗せるアプリケーションの負荷試験は、通常の負荷試験でよく用いられる観点に加えて、クラスタ特有の観点も確認していく必要があります。
適切にクラスタやPodが設定されていない場合、意図しないダウンタイムが発生したり、想定する性能を出すことができません。
そこで私が設計した観点を、汎用的に様々なPJでも応用できるよう整理しました。 一定の負荷、スパイク的な負荷をかけつつ、主に下記の観点を重点的に記載します。
- Podの性能
- Podのスケーラビリティ
- クラスタのスケーラビリティ
- システムとしての可用性
本記事ではこれらの観点のチェックリスト的に使えるものとしてまとめてみます。
![]()
確認観点
攻撃ツール
- 1: ボトルネックになりえないこと
Podレベル
- 2: 想定レイテンシでレスポンスを返せること
- 3: 想定スループットを満たせること
- 4: 突然のスパイクに対応できること
- 5: ノードレベルの障害、ダウンを想定した設定になっていること
- 6: 配置が想定どおりに行われていること
- 7: 新バージョンリリースがダウンタイム無しで可能なこと
- 8: 長時間運転で問題が起こり得ないこと
クラスタレベル
- 9: Podの集約度が適切であること
- 10: 配置するPodの特性に合わせたノードになっていること
- 11: 突然のスパイクに対応できること
- 12: クラスタの自動アップグレードの設定が適切であること
- 13: Preemptibleノードの運用が可能であるか
攻撃ツールの観点
1: 攻撃ツールがボトルネックになりえないこと
攻撃ツール(locust, JMeter, Gatlingなど)を使って、担保したいRPSの負荷を攻撃対象に対してかけることができるか
解説
意外と失念しがちですが、攻撃ツール自体が想定する負荷をかけられるとは限りません。
たとえば一つのマシンで大きな負荷をかけようとすればファイルディスクリプタやポート、CPUのコアなどが容易に枯渇します。
大きなRPSを扱う場合は、JMeterやlocustなど柔軟にスケールして、分散して負荷をかけることのできる環境を用意しましょう。
検証方法
私のPJではlocustのk8sクラスタを立て、同じクラスタ内にNginxのPodを立て、静的ページに対してリクエストさせてどのくらいのスループットが出るかを検証しました。
要件的には6000RPSほど担保すれば良いシステムだったので、workerの数やユーザの数を調整して余裕をもって8000RPSくらいまでは出せることを確認しました。
Podの観点
2: 想定レイテンシでレスポンスを返せること
Pod単体で想定するレイテンシでレスポンスを返すことができるか
解説
HPAを無効にしてPod単体の性能が要件を満たすかをまず確認します。
想定レイテンシを超過してしまう場合、Podのresource requestとlimitを積んでいきましょう。
また、もしアプリケーションに問題があってレイテンシが超過する場合はアプリケーションのチューニングが必要です。
3: 想定スループットを満たせること
Podレベルで見たときに想定するスループットを出すことができるか
解説
HPAを無効にしてPodを手動でスケールアウトしていき、どこまでスループットを伸ばせるかを確認します。
スケールアウトしてもスループットが伸びない場合、どこかにボトルネックが出ている可能性が高いです。
その場合まず私は下記を確認します。
各PodのCPU使用率
- 特定のPodだけCPU使用率が偏ってる場合はルーティングポリシーの再確認
各Podのレイテンシ
- 一つ前の「想定レイテンシでレスポンスを返せること」に戻って確認
攻撃側のCPU使用率
- 攻撃ツールのスケールアップ、スケールアウト
4: 突然のスパイクに対応できること
突然急激に負荷が高まったときに対応することができるか
解説
HPAを設定しておけばオートスケーリングしてくれますが、ポリシーを適切に設定する必要があります。
HPAは一定期間でPodの数をアルゴリズムに応じて算出し、定期的に調整することで実現されています。

よって、スケールする条件がギリギリに設定されていたりすると突然負荷が高まっても急にスケールできずに最悪ダウンタイムを挟んでしまったりします。
また、k8sの1.18からはスパイクで急激にPodが増えたり減ったりしすぎないように、behaviorという設定項目も追加されています。
私の場合はlocustで急激な負荷を再現し、下記の観点をチェックしました。
- 監視するメトリクスは適切か?
- 監視するメトリクスのしきい値は適切か?
- Podの増減制御が必要そうか?
5: ノードレベルの障害、ダウンを想定した設定になっていること
ノードが柔軟にダウンしてもServiceに紐づくPodレベルで正常にレスポンスを返し続けることができるか
解説
k8sは、クラスタのオートアップグレードなどでノードが柔軟にダウンしたり、 クラスタのオートスケールでノードがスケールインするので、かなりの頻度でPodが削除されて再作成されることを考慮する必要があります。
そこで注意することとして2つの観点があります。
1つ目はPodのライフサイクルです。
Podが削除されるとき、まずServiceからルーティングされないようにすることと、コンテナへのSIGTERMが同時に発生するため、ルーティングが止まる前にコンテナが終了しないようにする必要があります。
具体的にはlifecycle hookを使い、preStopでsleepしてルーティングが止まるまで待ちましょう。 Kubernetes: 詳解 Pods の終了
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 30"]
また、NEGなどを活用してContainer Nativeなロードバランシングを行っている場合、下記のような配慮も必要です。
【Kubernetes】GKEのContainer Native LoadbalancingのPodのTerminationの注意点
2つ目はPod Distruption Budgetです。
これを適切に設定しておくことで、ノードのアップデートなどでPodが排出される際に一気に排出されないよう制御することができます。 後述のノードのSurge Updateと合わせて確認するといいでしょう。
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: sample-service
spec:
maxUnavailable: "25%"
selector:
matchLabels:
app: sample-service
namespace: default
project: default
6: Podの配置が想定どおりに行われていること
Podが想定するノードに配置されているか、想定どおりに分散されているか
解説
Podの配置は何も考えないと空いているリソースからkube-schedulerが任意に選択してしまうため、下記のような観点の考慮が不可欠です。
特定のゾーン、ノードに集中して置かれてしまっている場合、いくらPodを冗長化したとしても、ノードのダウンや、ゾーン障害で一斉にサービスが止まる
Preemptibleノードなどを使っている場合は一斉に複数ノードが落ちることがある
- (通常ノードとPreemptibleノードは併用するのが定石になっています)
Container Native Loadbalancingを使用する場合、LBはPodに平等にルーティングするわけではなく、NEGに対して均等にルーティングしようとするため、NEG(つまりはゾーン)でPod数の偏りがあると安定性やスケーラビリティ、スループットに悪影響を与える
ディスクIO処理が多いPodなどはディスクタイプがssdのノードの配置するなど、Podの特性に応じたノード選択が必要かどうか
Podは、下記を活用することで配置制御を行うことができるので、これらを駆使して配置制御を行いましょう。
- TaintとToleration
- Pod Affinity
- Node Selector
- Node Affinity
- Topology Spread Constraints

7: 新バージョンリリースがダウンタイム無しで可能なこと
PodのDeploy戦略が正しく機能しているか
解説
これはチームのデプロイ運用方針でも変わりますが、一定の負荷をかけつつ、ダウンタイム無しでPodのバージョンを切り替えられるか検証しておくと良いと思います。
8: 長時間運転で問題が起こり得ないこと
長時間運用することによって顕在化する問題を含んでいないか
解説
アプリケーションの実装がイケてない場合、メモリリークや、ファイルディスクリプタの枯渇などがよく発生します。
1日以上負荷をかけ続けたときに消費が増加し続けるようなリソースがないか、ノードのスケールイン、スケールアウト、GKEならメンテナンスウィンドウの時間でも問題なく稼働し続けられているかは検証しておくと良いでしょう。
クラスタ観点
9: Podの集約度が適切であること
Podが効率的かつ安全にノードのリソースを活用できているか
解説
Podは、PodのRequestされたリソースと、ノード内の割当可能なリソースを加味してスケジューリングされます。
つまりRequestが適切に設定されていないとリソースが全然余っているのにどんどんノードが増えてしまったり、逆にスケールしてほしいのに全然スケールしてくれない、といったことが起こりえます。
GCPなどのダッシュボードや、kubectl topコマンドを用いてノードのリソースを有効に活用できているかをチェックしておきましょう。
10: 配置するPodの特性に合わせたノードになっていること
IOアクセスが頻繁なPodなど、特性に応じたノードが選択されているか
解説
特定のPodはSSDを搭載したNodeに配置されてほしいなど、Podに応じた要件がある場合、 Node Selector、Node Affinityを利用して適切に配置されているかを確認しましょう。
11: クラスタの自動アップグレードの設定が適切であること
クラスタの自動アップグレード設定が意図した通りになっていること
解説
例えばGKEを利用している場合、メンテナンスウィンドウとしてメンテナンス可能な時間を設定してあげることで、アクセスが少ない時間にアップグレードを行うなどの制御が可能です。 また、一気にノードが再起動しないようサージアップグレードを積極的に活用していきましょう。
12: 突然のスパイクに対応できること
クラスタがPodのスケールに追従し、スパイクに対応することができるか
解説
これは前述の集約度の話と共通していますが、PodのRequestによってどのようにしてノードがスケールするか、という点が決まります。
基本的に、GKEではスケジュールするためのノードが足りなくなって初めてスケールアウトします。 つまり、突然スパイクしてPodがスケールアウトしようとしたものの、配置できるノードが足りないため、まずノードがスケールアウトしてからPodのスケジューリングがされるケースが発生します。 このような場合にも突然のスパイクに耐えうるか、というのは検証しておく必要があります。
運用したいシステムの要件次第ですが、柔軟にスケールしたい場合はPodのHPAの設定をゆるくしたりなど工夫が必要になります。
13: Preemptibleノードの運用が適切であるか
Preemptibleノードへの過度なPodの集中など、意図しないリソースの使われ方をしていないか
解説
基本的に本番クラスタでPreemptibleノードOnlyで運用するのは危険です。 Preemptibleノードを運用する場合は、通常のノードと一緒に運用し、 かつTaintとTolerationを適切に設定して、Preemptibleノードによりすぎないようにしましょう。
まとめ
今回は私が負荷試験によって担保した、
- スケーラビリティ
- 可用性、安定性
- レイテンシとスループット
- リソース利用効率
の観点を整理しました。 もしご意見、感想あればぜひコメントなどいただけると嬉しいです!
【Kubernetes】GKEのContainer Native LoadbalancingのPodのTerminationの注意点
概要
最近のGKEはContainer Nativeなロードバランシングを推奨しています。 これは、Alias IP, NEGという仕組みを使って、GCPのロードバランサーがPodのIPに直接ルーティングすることができます。 しかし、適切にPodを設定していない場合、クラスタのメンテナンスなどでノードからPodがevictされたときにダウンタイムが発生してしまいます。 この記事ではContainer Native LoadBalancerの仕組みと、Podの適切な設定について説明していきます。
Container Nativeなロードバランシングの仕組み
Container Native LoadBalancingに記載してある通り、
 引用: Container Native LoadBalancing
引用: Container Native LoadBalancing
GKEのMasterノードにNEG ControllerというCustom Controllerがいて、特定のAnnotationがついたServiceが登録されたときに、GCPにNEGリソースを作成し、Serviceに紐づくPodをNEGにAttachするという仕組みのようです。 また、zonal network endpoint groupという名前の通り、各ゾーンごとにNEGはつくられ、Podは自分が存在するゾーンのNEGに所属する形になります。
Podの退避時に纏る注意点
GKEではクラスタを自動アップグレードしてくれるので、ノードがローリングアップデートされます。するとそのタイミングでスケジュールされていたPodは一旦吐き出されて別のノードに再作成されるため、ライフサイクルに注意しないとダウンタイムが発生してしまいます。
Podが退避されるときのライフサイクル
Podが退避され、一旦NEGから外れてルーティングされなくなる時、下記のようなフローになります。
- PodがTerminating状態へ
- 下記が同時に走る
- ServiceのEndpointから退避されたPodが外れる
- PodのpreStop + SIGTERM処理が走る
- ServiceからPodが外れたことを検知してNEG ControllerがNEGからPodを外す
- GCLBが、退避されたPodにルーティングしなくなる
つまり、ここで意識しないといけないポイントは2点です。
- NEGから外れる前にPodが停止しないようにする
- NEGから外れても処理中のリクエストだけは処理完了させる
具体的な対応
1に関しては、PodにpreStopを適切に実装しましょう。 基本的なServiceによるルーティングのときと一緒ですね。
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 20"]
2に関しては、GCLBのBackendの設定にコネクションドレインを設定しておきましょう。
Ingressを使用している場合は、CRDで設定することもできます。 BackendConfig パラメータによる Ingress 機能の構成
そして1のsleepの時間はコネクションドレインの時間より長く設定しておく必要があります。
確認方法
locustやApache Benchなどを使って一定負荷をかけつつ、drainコマンドを使ってノードからPodを退避させてもダウンタイム無しで安全に移動ができてることがわかるかと思います。
サンプル
kubectl drain gke-service-1-service-1-nodes-320d8165-7p7p --ignore-daemonsets --delete-local-data
まとめ
Container Load Balancingはとても強力な仕組みですが、 基本的なServiceのルーティング、LBの設定の考え方を踏襲し、忠実に設定してあげる必要があります。
【Kubernetes】マルチクラスタの最適なヘルスチェックとFailOverについての考察
概要
ここ最近関わっているプロジェクトで、 クラスタを安全にBlue/Greenで更新するためにマルチクラスタ構成にして冗長化する案件を推進していました。 クラスタの安全な更新とクラスタのHealth Check、Fail Overは切っても切れない関係にあります。 そこで得られた、どのような目的で、どのような構成でヘルスチェックするべきか、という1意見を記述してみます。
想定の構成
Istioが入っており、LBはまずIstio Ingress Gatewayにルーティングし、Ingress Gatewayでクラスタ内の各サービスにルーティング
- (これによってGCLBからのトラフィックに対してもIstioのproxyルールを適用させる)

なぜクラスタを冗長化するのか?
クラスタのアップデート、Istioのバージョンアップデート時にダウンタイム無しで安全に更新するために冗長化しています。 InPlaceでUpdateするのではなく、 一度レプリカクラスタをLBから切り離して更新し、もう一度LBに紐づけ、 しばらく様子を見て問題なさそうならメインのクラスタも更新する、という方針をとっています。 またシステムのユーザへの影響を最小にするためにも、クラスタに問題があったときにまだ更新していないクラスタにちゃんとFail Overさせたいので、 ヘルスチェックの定義がとても重要になってきます。
ヘルスチェックを定義する上での課題
本来クラスタ自体の更新といえども、どのサービスにどんな影響を与えるかは各サービス依存です。 例えば、クラスタの中にはバージョン依存のリソースを使っているサービスもあり、アップデートすると一部壊れてしまうかもしれません。
よって、
といったような方針で安全を担保することが考えられます。
しかし1は現状構成が複雑になりがちであり、 2に関していえば特定のサービスだけの障害がクラスタ全体に波及してしまうため論外です。
(たとえばあるサービスに障害が出たときに、クラスタ全体でFail Overされてしまい、仮にFail Over先もヘルスチェックに通っていなかったときにLBからみてルーティング先がなくなる)
とはいえ、クラスタ更新起因でサービスに障害が発生したときに検知してFail Overする必要あります...
ではどうすればいいでしょうか?
採用した方針
ニーズに応じてヘルスチェックの内容を変えることにしました。
本来サービスの可用性は、CanaryやBlue/Greeなどを駆使してサービスのレイヤーで担保するべきであり、サービスすべての状態を検知する必要があるのはクラスタの更新中の間だけです。
よって、
ヘルスチェック用のサービスを実装
- 全サービスのヘルスチェックを行い、すべて健康ならOK、そうじゃないならNGを返すエンドポイントを提供 ※1
- 何もせず200を返すエンドポイントを提供
クラスタ更新中はGCLBのヘルスチェックは、Istio IngressGatewayを通して1のエンドポイントを見に行く
- 更新が落ち着いたらFeature Toggleなどで、GCLBが見るヘルスチェックエンドポイントを2に切り替える ※2
という方針を採用しました。

これにより、クラスタ更新中はかなりシビアに全サービスをチェックし、 それ以外のときは、Istioの疎通だけ死んでいないことだけ担保して、サービスの可用性担保はサービスのレイヤに任せる、 といった方針を実現しています。
補足
- ※1 実施自体は裏で非同期で行い、エンドポイントに問い合わせが来たら最新のスナップショットから結果を返す
- ※2 Istio IngressGatewayを通すことでクラスタ全体でIstio起因で疎通が死んでいないことを担保する
まとめ
今回、普段はクラスタはIstioの疎通まで担保できてたら健康とし、サービスごとの可用性はサービスに任せるという思想で、 見るべきヘルスチェックエンドポイントを切り替えるという方針を取りました。 アーキテクチャの良し悪しは運用してはじめて明らかになるので、しばらく運用して所感を別の機会に振り返りたいと思います。
Istioはいかにしてサービス間通信のセキュリティを担保しているのか?
この記事について
この記事では、Istioがどのような考え方でサービス間通信のセキュリティを担保し、 どのように担保しているかを概観レベルで整理する。
サービス間通信で担保したいものと従来のセキュリティモデル
サービス間通信として担保したいものとして、 通信するアクセス元を制御し、盗聴やなりすまし、改ざんといった攻撃から守ることが挙げられる。 つまり、
- man in the middle攻撃への防御
- アクセス制御
がセキュリティ要件として挙げられる。 従来のセキュリティモデルとしては、 プライベートネットワークを構築し、IPベースでアクセス元を制限することでこれらを担保してきた。 (AWSのPrivate VPCとSGがわかりやすい)
Istioではどういうアプローチをとったのか?
昨今のコンテナベースで構築されるシステムでは、IPアドレスは高頻度で動的に変更されるためこのアプローチだと破綻する。 そこでIsitoは各ワークロードに対してIDを定義し、IDベースでアクセス制御を行うことととした。 具体的にはどういうアプローチなのか?
コアコンセプト
ワークロードに割り振られたIDをベースとしてTLS通信することで認証と暗号化通信をし、 認証されたIDに対する認可制御を行うことでアクセス制御を実現している。 そのために下記の仕組みを実装している。
- ワークロードに一意のIDを割り振る
- IDを認証するための証明書の発行、配布、ローテーション
これらは、SPIFFE(Secure Production Identity Framework For Everyone)と呼ばれる標準仕様で定義されており、IstioはCitadelコンポーネントがこれを踏襲した実装にあたる。 具体的なSPIFEEの仕様、フローはSPIFFEとその実装であるSPIREについてでわかりやすく言及されている。

ポイント
つまり、ワークロードのためのID、証明書を発行し、登録しておくための認証局としての役割を担ったisdiod(Citadel)が存在し、各ノードに存在するistio-agentが、このCitadelとistio proxyの間のやり取りを仲介し、証明書配布などを行っている。 (istio proxyのSDSはこのagentが担当している) これによって、Podが大量に存在するような大規模クラスタでも、Pod自体はistio agentによって分割統治されているので、istiodに対しての負荷をかなり抑えることができる。
また、通常想定されるTLSと違い、この証明書の期限は非常に短く設定されていて、頻繁にローテーションされている。 これによって攻撃者は攻撃を継続していくためにはこの証明書をローテーションされるたびに逐一盗み出さなくてはならず、攻撃の難易度を上げている。
まとめ
このようにIstioはワークロードレベルで認証し、それぞれにアクセス制御を設けている。 これによって動いているプラットフォームに左右されず、どのような環境においても安全な通信を実現することができる。