Istio + Argo Rolloutとカナリアリリース
本記事について
Argo Rolloutを導入すると、様々なデプロイ戦略を実践することができる。 ただ少し実際の運用イメージが見えづらかったので整理してみる。
Argo Rolloutについての概要
Argo Rolloutとは通常のk8sのDeploymentに加え、カナリアリリースなどの様々なアップデート戦略をサポートするためのコンポーネント。 Rolloutという、Deploymentに対し、様々なPodのアップデート戦略をつけ加えたCRDを用いる。 Deployment同様に内部ではReplicaSetを管理していて、 アップデートのたびに新しいReplicaSetを作り、設定の通りにPodを移行させる。
カナリアリリース
一部のリクエストを新しいバージョンに流し、なにかあればロールバック、何も無ければ徐々にトラフィックを増やし、最終的に100%に切り替える。 ArgoRolloutでは、Rolloutリソースにどのように移行していくかをステップごとに宣言する。 設定できるのは下記のような項目。
- setWeightでカナリアバージョンの比重を設定する
- pauseでその状態でどのくらい待機するかを定義する
- analysisで同期的な新バージョンのヘルスチェックを挟む
ヘルスチェックについて
B/Gやカナリアの場合、定期的にヘルスチェックを行い、失敗した場合にロールバックすることができる。 実際にはAnalysisTemplateに記述し、Rolloutで指定することで、実行時にAnalysisRunリソースが作られ、 指定したヘルスチェックを実行する。 AnalysisTemplateでは、下記の実行形式をサポートしている。
Prometheusサーバからのメトリクス取得
- 一定時間内の200エラーが95%以上など
- 一定時間内の5xx系エラーが1%以下など
Job Metrics
WebHook
ちなみにAnalysisを定義しない場合はロールバックは自動で行わない。
結局Argo Rolloutを使って担保されるものはなに?
- 自動的な比重の変更と自動的なモニタリング + ロールバック
カナリアリリースの想定実行フロー
- 新バージョンデプロイ => 数%のトラフィックを新バージョンへ流す => 一定時間経って問題なければ自動的に新バージョンをStableバージョンを切り替え
- 新バージョンデプロイ => 数%のトラフィックを新バージョンへ流す => manual approveで新バージョンをStableバージョンへ切り替え
やらないといけないこと
- DeploymentはRolloutに置き換える
- カナリアリリース用のServiceを作成する
- VirtualServiceでカナリアリリースサービスとStableリリース用サービスで比重を0%, 100%に設定しておく
- ヘルスチェック用のリソース定義(AnalysisTemplate)
- Rolloutでstable用Service, canary用Service, virtualService, AnalysisTemplateを指定しておく
挙動FAQ
Podが存在しないときはどうなる?
- Deploymentと同様で、UpdatePolicyによらず、新規のReplicaSetおよびPodが作られる
どのようにWeightをコントロールしている?
Istioと連携するとどうなる?
- ルーティングがリクエストの割合ベースで分散できる
- WeightはArgoRolloutのPodがVirtualServiceの設定を随時書き換えている
カナリア用のServiceの向き先はStableと同じでいいの?
- 良い。Argo Rolloutが随時Serviceのセレクタに条件を付け足している
How to Use
- https://argoproj.github.io/argo-rollouts/getting-started/
- https://argoproj.github.io/argo-rollouts/features/canary/#canaryservice
- https://argoproj.github.io/argo-rollouts/features/analysis/#job-metrics
- https://argoproj.github.io/argo-rollouts/features/traffic-management/istio/
設定例
- stable = v1, canary = v2のケース
- AnalysisTemplateを使って、500エラーが一定期間内に3回でたらNGという定義を行っている
- istioが持つprometheusに対してクエリを投げている
- この設定では、比重を10%にし10分待ち、以降徐々に10分毎に20%ずつ増やす。50%になったら、そのまま待ち手動によるResumeを待つ。
apiVersion: v1
kind: Service
metadata:
name: reviews
labels:
app: reviews
service: reviews
spec:
ports:
- port: 9080
name: http
selector:
app: reviews
---
apiVersion: v1
kind: Service
metadata:
name: reviews-canary
labels:
app: reviews
service: reviews
spec:
ports:
- port: 9080
name: http
selector:
app: reviews
---
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: reviews
labels:
app: reviews
spec:
replicas: 1
selector:
matchLabels:
app: reviews
template:
metadata:
labels:
app: reviews
version: v2
spec:
serviceAccountName: bookinfo-reviews
containers:
- name: reviews
image: docker.io/istio/examples-bookinfo-reviews-v2:1.15.0
volumes:
- name: wlp-output
emptyDir: {}
- name: tmp
emptyDir: {}
strategy:
canary:
analysis:
templates:
- templateName: failure-count
args:
- name: service-name
value: reviews-canary.default.svc.cluster.local
stableService: reviews
canaryService: reviews-canary
trafficRouting:
istio:
virtualService:
name: reviews
routes:
- primary
steps:
- setWeight: 10
- pause: { 10m }
- setWeight: 30
- pause: { 10m }
- setWeight: 50
- pause: { }
---
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: failure-count
spec:
args:
- name: service-name
metrics:
- name: failure-count
interval: 30s
failureCondition: result >= 3
failureLimit: 3
provider:
prometheus:
address: "http://prometheus.istio-system.svc.cluster.local:9090"
query: |
sum(irate(
istio_requests_total{reporter="source",destination_service=~"{{args.service-name}}",response_code!~"5.*"}[30s]
))
GitOpsとの兼ね合い
カナリアリリースが完了し、100%新バージョンに移行したあとに同期されたらどうなる?
- 結論: 何も変わらない
- ArgoRolloutがいじった結果とリソースが一緒になる
- StableとCanaryのServiceの向き先が両方共新Podになっていて、VirtualServiceもStableに100%向ける設定になっている
- 結論: 何も変わらない
カナリアリリース実行中に同期されたらどうなる?
- 結論: 一度ルーティングの割合がStable 100%, Canary 0%にリセットされた後、Rolloutによって同期される直前の状態に戻される
カナリアリリース時と通常リリース時でのフローの違い
デバッグ方法
- RolloutとAnalysisRunリソースを見るとデプロイの挙動が分かる
kd rollouts.argoproj.io kd analysisruns.argoproj.io
Analysisの設定は実運用上どうすれば良い?
IstioでPrometheusを有効にしてインストールし、Istioのメトリクスによって判別する
- --set values.prometheus.enabled=trueをつけてistioctl manifest applyすればprometheusが有効になるので、これをつかってメトリクスを取得することはできる
- ただ、素直に入れても可用性は担保されていないので、別途冗長化するなどの可用性対応が必要になってくる
Stackdriverなどにメトリクスを集約している場合、Goなどでデータを引っ張ってきた上で判定する
カナリアリリースした結果失敗してロールバックしたよね、というのはどのように検知すればよいか?
- Argo Rolloutの機能では通知できないので、自前の検証プログラムを使ってAnalysisRunを動かす場合は、プログラムの中にエラーケースでアラートするように記載しておく
- 例えばStackdriverならCloud Monitoringを活用して、ロールバック条件と同じ条件でアラートが飛ぶようにポリシー設定しておく
【GCP Anthos】 Fail Overの挙動から最適なマルチクラスタ構成を考える
記事の目的
前回の記事でIngress For Anthosを用いてRegionにまたがったKubernetsのマルチクラスタを構築した。 今回は1段深く掘り下げて、クラスタ内に複数のフロントサービスを持つケースを考える。 このケースでAnthosで構築したマルチクラスタのFail Overの挙動を詳しく検証し、 どんなときに、どんな条件でFail Overするのかを整理する。 また、それによって最適なマルチクラスタ構成を考える。 今回はIstioはマルチコントロールプレーン構成にしないので、クラスタ内のサービス間通信のFail Overについてはとりあげない。 【GCP Anthos】 Regionに跨って冗長化したKubernetsのマルチクラスタをロードバランシングする
題材となるサービス
今回は少し実運用を考慮し、クラスタ内に2つのフロントサービス(外部から直接ルーティングされてくるサービス)を作り、それぞれへはIngressGatewayでルーティングすることとする。

GCLB + NEGsのFailOverの検証
Anthosはクラスタ間のロードバランシングにGCPのCloud Loadbalancer(以下GCLB)とクラスタ内の任意のPodに紐付いたNEGを使う。 よってまずはGCLB + NEGの構成のFailOverの挙動をまずは整理する。
事前準備
- 東京クラスタ
- GKE 1.15
- Anthosへのメンバー登録済み
- istioインストール済み(v1.5.1)
- 台湾クラスタ
- GKE 1.15
- Anthosへのメンバー登録済み
- istioインストール済み(v1.5.1)
アプリケーションのデプロイ
ホストヘッダーによってbookinfoとzoneprinterへのルーティングの向き先を変更するようにしている。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: zoneprinter
spec:
hosts:
# - "*"
- "www.zoneprinter.com"
gateways:
- single-gateway
http:
- match:
- uri:
exact: /
- uri:
exact: /ping
- uri:
exact: /location
route:
- destination:
host: zoneprinter
port:
number: 80
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "*"
# - "www.bookinfo.com"
gateways:
- single-gateway
http:
- match:
- uri:
exact: /
- uri:
exact: /productpage
- uri:
prefix: /static
- uri:
exact: /login
- uri:
exact: /logout
- uri:
prefix: /api/v1/products
fault:
abort:
httpStatus: 503
percentage:
value: 100.0
route:
- destination:
host: productpage
port:
number: 9080
MCI, MCSリソースのデプロイ
一つのMCSを一つのIngress GatewayのPodに割り当てている。
FailOverの検証方法
MultiClusterServiceが一つなのでIngress GatewayのPodに紐付いた単一のNEGが作られる。 よってこのままだと、ヘルスチェックに使用できるパスが一つのフロントサービスへのルーティングのみになってしまうが、一旦このまま検証する。
- ヘルスチェック対象のサービス = zoneprinter, ヘルスチェック非対象のサービス = bookinfo
- ホストヘッダーがwww.bookinfo.comのものはbookinfoへ、それ以外はzoneprinterへルーティング
- ヘルスチェックは、
/のパスへ - ダウンさせるサービスは、IstioのFault Injectionを利用し、エラーが常に返却されるように
- サンプルコードはこちら
GCLB + NEGのFail Overの挙動結果まとめ
ヘルスチェック対象でないサービスがダウン
ヘルスチェック対象のサービスがダウン
Fail Over条件のカスタマイズは不可能
つまり、ヘルスチェックによってのみFail Overするかどうかが決まる。 よって、今の構成だと、ヘルスチェック対象のサービスがUnhealthyの場合、 引きずられてHealthyなサービスまでも、冗長化された別クラスタにFail Overされてしまう。
理想的な挙動はなにか?
フロントサービスに対して個別にヘルスチェックを実施し、 一つのフロントサービスのヘルスチェックステータスが他のサービスのルーティングに影響しないようにしたい。 つまり、今回ならzoneprinterがUnhealthyだからといって、bookinfoまで別クラスタにルーティングしないでほしい。
どういう構成にするべきか
ようは各フロントサービスごとにヘルスチェックしてほしい => 各サービスごとにNEGが作られて、それらがGCLBのバックエンドとして設定されてほしいということになる、 よってフロントサービスの数だけMultiClusterServiceを作成し、単一のIngressGatewayに紐付けることにした。

補足
ちなみに、各フロントサービスに対して直接NEGを紐付ければいいのでは?と思うかもしれないが、 そうなるとIngressGatewayのEnvoyを通過せずに直接リクエスト先サービスのPodにルーティングされてしまうので、 VirtualServiceやDestinationRuleの設定が無視されてしまう。 この辺の挙動のイメージは、こちらにまとめた。 また、IngressGatewayのPodへのNEGを作るので、IngressGatewayにアタッチされているL4のGCLBは不要になる。 よってIstio Operatorなどを使ってNodePortに変更する。
実際のコード
apiVersion: cloud.google.com/v1beta1
kind: BackendConfig
metadata:
name: multi-gateway-bookinfo-cfg
namespace: istio-system
spec:
healthCheck:
checkIntervalSec: 15
timeoutSec: 10
healthyThreshold: 1
unhealthyThreshold: 2
type: HTTP
port: 80
requestPath: /
hostHeader: "www.bookinfo.com"
---
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: multi-gateway-bookinfo
namespace: istio-system
annotations:
beta.cloud.google.com/backend-config:
'{"ports": {"80":"multi-gateway-bookinfo-cfg"}}'
spec:
template:
spec:
selector:
app: istio-ingressgateway
ports:
- name: multi-gateway-bookinfo
protocol: TCP
port: 80
targetPort: 80
---
apiVersion: cloud.google.com/v1beta1
kind: BackendConfig
metadata:
name: multi-gateway-zoneprinter-cfg
namespace: istio-system
spec:
healthCheck:
checkIntervalSec: 15
timeoutSec: 10
healthyThreshold: 1
unhealthyThreshold: 2
type: HTTP
port: 80
requestPath: /
hostHeader: "www.zoneprinter.com"
---
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: multi-gateway-zoneprinter
namespace: istio-system
annotations:
beta.cloud.google.com/backend-config:
'{"ports": {"80":"multi-gateway-zoneprinter-cfg"}}'
spec:
template:
spec:
selector:
app: istio-ingressgateway
ports:
- name: multi-gateway-zoneprinter
protocol: TCP
port: 80
targetPort: 80
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
name: multi-gateway
namespace: istio-system
spec:
template:
spec:
rules:
- host: "www.bookinfo.com"
http:
paths:
- path: /
backend:
serviceName: multi-gateway-bookinfo
servicePort: 80
- host: "www.zoneprinter.com"
http:
paths:
- path: /
backend:
serviceName: multi-gateway-zoneprinter
servicePort: 80
backend:
serviceName: multi-gateway-zoneprinter
servicePort: 80
確認
この状態でbookinfoのヘルスチェックエンドポイントに対してFaultInjectionし、 zoneprinterにcurlすると、
❯❯❯ curl -H "Host:www.zoneprinter.com" http://35.241.18.9/location <!DOCTYPE html> <h4>Welcome from Google Cloud datacenters at:</h4> <h1>Tokyo, Japan</h1> <h3>You are now connected to "asia-northeast1-a"</h3> <img src="https://upload.wikimedia.org/wikipedia/en/9/9e/Flag_of_Japan.svg" style="width: 640px; height: auto; border: 1px solid black"/>
となり、引きずられてFailOverしていないことが分かる。
また、逆にzoneprinterにFaultInjectionし、 bookinfoにアクセスすると、 台湾クラスタの方のログにアクセスが来たことが分かる。
まとめ
- GCLBはヘルスチェックによってのみFailOverする
- MCSに対して一つずつNEGが作られるので、複数のNEGを作ることで複数のフロントサービスに対してヘルスチェックを行うことができ、サービスごとにFailOverできる
- 今回のコード
IstioのTraffic Managementの動作イメージを掴もう
本記事について
Istioを使う上で、Traffic Managementを司るVirtual Service, DestinationRuleについて、 どう作用しているのかという点がわかりにくかったため、本記事にて整理し実際に動かしながら検証する。 前提として、サービスメッシュやEnvoyの基本的な設定についてはざっくりと理解している読者を想定している。
Istioとは?
Istioは、サービスメッシュの機能を統括的に導入、管理を行うためのOSSである。 内部ではEnvoyを使用していて、IstioとしてはとしてはこのEnvoyのコントロールプレーンとしての機能も担っている。 What is Istio?
主に、
Traffic Management
- 割合やヘッダーによるルーティングのコントロールやロードバランシングなどを行うための機能
- Envoyの機能であるような、サーキットブレーカー、Fault Injectionなどの機能も基本的に使える
Observability
- Promheusなどメトリクスを集計するためのソフトウェアにデータを転送する機能
Security
- mTLS通信による認証された通信や、JWTを活用した認可処理をプロキシとして挟んだりすることができる
- mTLSに用いられる証明書はIstioが独自証明書を発行してくれ、特に意識せずともmTLSをサービス間通信に導入することができる
といった機能を提供しており、Kubernetsなどのプラットフォーム連携が充実している。
Traffic Managementについて
Istioは、k8sにデプロイされたPodに自動的にサイドカーとしてEnvoyベースのProxyをInjectする機能が備わっている。 基本的には、リクエスト元サービス -> Envoy -> Envoy -> リクエスト先サービスという流れで通信することになる。 そして、このEnvoyが実際にルーティングの制御を行っている。 このEnvoyに設定情報を提供するのがk8sのCRDである下記3種類のリソースである。
- Virtual Service
- DestinationRule
各リソースについての概念説明などはなどは、 公式ドキュメント に記載されている通りである。 このさきは、minikubeにIstioと、Istioのデモアプリである、Bookinfo をデプロイして挙動を確認していく。
事前準備
- minikube v1.9.2
- Istio v1.5.2
- Kubernets v1.18.0
Ingress Gatewayの実態を見てみよう
初期状態
Ingress Gatewayを有効にしてIstioをk8sのクラスタにインストールすると、
- Service(Load Balancer Type)
- Deployment
のリソースがそれぞれ作られていることが分かる。
❯❯❯ kubectl get service -n istio-system istio-ingressgateway LoadBalancer 10.103.255.236 10.103.255.236 15020:31097/TCP,80:31587/TCP,443:32153/TCP,15029:30056/TCP,15030:32475/TCP,15031:32379/TCP,15032:32322/TCP,31400:32143/TCP,15443:32376/TCP 3d15h
❯❯❯ kubectl get deployments.apps -n istio-system NAME READY UP-TO-DATE AVAILABLE AGE istio-ingressgateway 1/1 1 1 3d15h
そして、このDeploymentによって管理されているPodの定義を見てみると、
❯❯❯ kubectl get pod -n istio-system istio-ingressgateway-6489d9556d-sp8f2 -o yaml | grep image:
image: docker.io/istio/proxyv2:1.5.2
のようになっているのが分かる。 このproxyvというのが中でEnvoyが動いてる。 この状態でRoutingの設定を覗いてみると、まだなにも定義していないためすべて404になるようになっている。
❯❯❯ istioctl -n istio-system proxy-config route istio-ingressgateway-6489d9556d-sp8f2 -o json | yq -y '.' -
- name: http.80
virtualHosts:
- name: blackhole:80
domains:
- '*'
routes:
- name: default
match:
prefix: /
directResponse:
status: 404
validateClusters: false
GatewayリソースとGatewayリソースに紐付けたVirtualServiceの作成
では次に下記リソースをapplyし、IngressGatewayにAttachしたGatewayリソースと、VirtualServiceを作ってみる。
❯❯❯ kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
そうすると、下記のようなルーティングルールが作成されている。
❯❯❯ istioctl -n istio-system proxy-config route istio-ingressgateway-6489d9556d-sp8f2 -o json | yq -y '.' -
- name: http.80
virtualHosts:
- name: '*:80'
domains:
- '*'
- '*:80'
routes:
...
- match:
path: /productpage
caseSensitive: true
route:
cluster: outbound|9080||productpage.default.svc.cluster.local
timeout: 0s
retryPolicy:
retryOn: connect-failure,refused-stream,unavailable,cancelled,resource-exhausted,retriable-status-codes
numRetries: 2
retryHostPredicate:
- name: envoy.retry_host_predicates.previous_hosts
hostSelectionRetryMaxAttempts: '5'
retriableStatusCodes:
- 503
maxGrpcTimeout: 0s
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/bookinfo
decorator:
operation: productpage.default.svc.cluster.local:9080/productpage
...
このように、IngressGatewayにAttachしたGatewayを作成し、さらにそのGateway指定したVirtual Serviceを作ると、 L4/LBから直接ルーティングされてくるEnvoyにルーティングルールが追加される。 また、向き先としてはPodのIPが解決されている。
❯❯❯ istioctl -n istio-system proxy-config endpoint istio-ingressgateway-6489d9556d-sp8f2 -o json | yq -y '.' - | grep "outbound|9080||productpage.default.svc.cluster.local" -A 30
- name: outbound|9080||productpage.default.svc.cluster.local
addedViaApi: true
hostStatuses:
- address:
socketAddress:
address: 172.17.0.12
portValue: 9080
weight: 1
Gatewayに紐付けないVirtualService
次に下記リソースをapplyし、reviewsサービスにはv2に50%、v3に50%の割合でルーティングされるようにしてみる。
❯❯❯ kubectl apply -f samples/bookinfo/networking/destination-rule-reviews.yaml ❯❯❯ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-v2-v3.yaml
まずIngress Gateway側のEnvoyの設定を確認する。
❯❯❯ istioctl -n istio-system proxy-config route istio-ingressgateway-6489d9556d-sp8f2 -o json | yq -y '.' -
今回はGatewayにAttachしていないVirtualServiceを作成したので、特にルーティング設定に変化がないことが分かる。
ではアプリケーション側のPodに配置されたEnvoyの設定はどうだろうか?
❯❯❯ istioctl proxy-config route productpage-v1-7f44c4d57c-nfnjd -o json | yq -y '.' -
- name: reviews.default.svc.cluster.local:80
domains:
- reviews.default.svc.cluster.local
- reviews.default.svc.cluster.local:80
routes:
- match:
prefix: /
route:
weightedClusters:
clusters:
- name: outbound|80|v2|reviews.default.svc.cluster.local
weight: 50
- name: outbound|80|v3|reviews.default.svc.cluster.local
weight: 50
timeout: 0s
retryPolicy:
retryOn: connect-failure,refused-stream,unavailable,cancelled,resource-exhausted,retriable-status-codes
numRetries: 2
retryHostPredicate:
- name: envoy.retry_host_predicates.previous_hosts
hostSelectionRetryMaxAttempts: '5'
retriableStatusCodes:
- 503
maxGrpcTimeout: 0s
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/reviews
decorator:
operation: reviews:80/*
長いので省略しているが、reviewsへのトラフィックのときに下記2つの向き先へ50%の割合でルーティングしているのが分かる。
endpointの設定を見てみると、それぞれv3のPodのIP、v2のPodのIPを指していることが読み取れる。
❯❯❯ istioctl proxy-config endpoint productpage-v1-7f44c4d57c-nfnjd -o json | yq -y '.' - | grep reviews -A 30
- name: outbound|9080|v3|reviews.default.svc.cluster.local
addedViaApi: true
hostStatuses:
- address:
socketAddress:
address: 172.17.0.10
portValue: 9080
- name: outbound|9080|v2|reviews.default.svc.cluster.local
addedViaApi: true
hostStatuses:
- address:
socketAddress:
address: 172.17.0.11
portValue: 9080
ちなみにこのルーティング設定は、Bookinfoアプリケーション内のそれぞれのサービスのサイドカーEnvoyの設定に組み込まれている。 (正確にはIstio Pilotの仕組みを使って設定が動的にInjectされている) つまり、リクエストを送る側、つまりクライアント側のプロキシ(Envoy)でロードバランシング、ルーティング制御を行い、Podにトラフィックを送っているのである。
DestinationRuleを削除してみる
最後に上記までの状態からDestinationRuleだけ削除してみる。
❯❯❯ kubectl apply -f samples/bookinfo/networking/destination-rule-reviews.yaml
ルーティングルールとしては変化していないように見える。
❯❯❯ istioctl proxy-config route productpage-v1-7f44c4d57c-nfnjd -o json | yq -y '.' -
clusters:
- name: outbound|80|v2|reviews.default.svc.cluster.local
weight: 50
- name: outbound|80|v3|reviews.default.svc.cluster.local
weight: 50
だが、エンドポイント定義としてはv2, v3が消えてしまっているのが分かる。
❯❯❯ istioctl proxy-config endpoint productpage-v1-7f44c4d57c-nfnjd -o json | yq -y '.' - | grep reviews - name: outbound|9080||reviews.default.svc.cluster.local
まとめ
【GCP Anthos】Anthos Service Mesh + Ingress For Anthosを組み合わせたk8sのマルチクラスタを構築する
この記事について
前回の記事でIngress For Anthosを使ったマルチクラスタによるk8sの冗長化について触れた。 今回はManagedなIstioを提供するAnthos Service Meshも取り入れ、 サービスメッシュを導入したマルチクラスタを実際に構築してみる。
Anthos Service Meshとは?
- 基本的にはIstioだが、Configuration ProfileがAnthos用にカスタムされて提供されている。
- 諸々Managedな代わりに色々制約がある。
- サポート機能
何がマネージドになっているのか?
サービスの依存関係、SLOモニタリング、各サービスのメトリクス収集がManagedに集約され、ダッシュボードで統括的にみることができる
- Istio Proxyのmetrics送信部分がおそらくManagedになっていて、ほぼ何もしなくてもAnthosに自動的に送られるようになっているぽい
GKE環境下ではCitadelがManagedになっていて、ルート証明書、サーバ証明書周りの管理をGoogleに任せられる
- ほぼ何も意識せずにmTLS機能を有効にできる
- Cloud IAPと連携ができる(GCPのサービスアカウントによる認証プロキシをメッシュに挟める)
Traffic DirectorがManagedなIstio Pilotとして提供されているらしい(まだ未検証)
クラスタの要件
- 4つのvCPUを持つ、n1-standard-4のノードが4つ以上存在すること https://cloud.google.com/service-mesh/docs/gke-install-existing-cluster#requirements
Your GKE cluster must meet the following requirements: - At least four nodes. If you need to add nodes, see Resizing a cluster - The minimum machine type is n1-standard-4, which has four vCPUs. If the machine type for your cluster doesn't have at least four vCPUs, change the machine type as described in Migrating workloads to different machine types - Use a release channel rather than a static version of GKE
本記事で構築するクラスタのアーキテクチャ図
- アプリケーションとしては、Istioで用意されているでもアプリのBooknfoを用いる。

- 注意点としては、
事前準備
n1-standard-4, 4つのvCPUのインスタンスを余裕を持って5つ程度でノードプールを構築し、クラスタを作っておく
手順について
基本的にはこの手順でIstioをインストールする ドキュメントの通りではあるが、ピックアップした手順を記載しておく。
Anthosの仲間に加える
- role/gkehub.connectの権限を持ったサービスアカウントを作成する
- 環境変数の設定
export PROJECT_ID=
export PROJECT_NUMBER=
export CLUSTER_NAME=
export CLUSTER_LOCATION=
export WORKLOAD_POOL=${PROJECT_ID}.svc.id.goog
export MESH_ID="proj-${PROJECT_ID}"
export SERVICE_ACCOUNT_NAME=anthos-connector
export SERVICE_ACCOUNT_KEY_PATH=
- クラスタをAnthosの仲間に加える
gcloud container hub memberships register $CLUSTER_NAME \
--gke-cluster=${CLUSTER_LOCATION}/${CLUSTER_NAME} \
--service-account-key-file=$SERVICE_ACCOUNT_KEY_PATH
Anthos Service Meshの設定
- クラスタのラベルにメッシュIDを設定(モニタリングに用いられる)
gcloud container clusters update ${CLUSTER_NAME} \
--update-labels=mesh_id=${MESH_ID}
gcloud container clusters update ${CLUSTER_NAME} \
--workload-pool=${WORKLOAD_POOL}
- Stackdriver MonitoringとLoggingを有効化
gcloud container clusters update ${CLUSTER_NAME} \
--enable-stackdriver-kubernetes
- 自分にクラスタ管理者のロールを当てる
kubectl create clusterrolebinding cluster-admin-binding \ --clusterrole=cluster-admin \ --user="$(gcloud config get-value core/account)"
Anthos Service Mesh用のConfiguration Profileを用いてIstioをインストールするため、Anthos用のistioctlをダウンロードする
Anthos Service MeshのIstioをInstall
istioctl manifest apply --set profile=asm \
--set values.global.trustDomain=${WORKLOAD_POOL} \
--set values.global.sds.token.aud=${WORKLOAD_POOL} \
--set values.nodeagent.env.GKE_CLUSTER_URL=https://container.googleapis.com/v1/projects/${PROJECT_ID}/locations/${CLUSTER_LOCATION}/clusters/${CLUSTER_NAME} \
--set values.global.meshID=${MESH_ID} \
--set values.global.proxy.env.GCP_METADATA="${PROJECT_ID}|${PROJECT_NUMBER}|${CLUSTER_NAME}|${CLUSTER_LOCATION}" \
--set values.global.mtls.enabled=true
- 任意のnamespaceに対してSidecarのAuto Injectionをdefault有効にする
kubectl label namespace default istio-injection=enabled
アプリケーションのデプロイ
下記のプロジェクトをダウンロードしてくる
ServiceとDeploymentリソースをデプロイ
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
- VirtualServiceをデプロイ
kubectl apply -f samples/bookinfo/networking/virtual-service-all-v1.yaml
- DestinationRuleをデプロイ
kubectl apply -f samples/bookinfo/networking/destination-rule-all-mtls.yaml
kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
Ingress For Anthosと連携する
- Config用のクラスタを登録(本記事ではアプリケーションと兼用している)
gcloud alpha container hub ingress enable \ --config-membership=projects/$PROJECT_ID/locations/global/memberships/$CLUSTER_NAME
[
{
"op": "replace",
"path": "/spec/type",
"value": "NodePort"
},
{
"op": "remove",
"path": "/status"
}
]
kubectl -n istio-system patch svc istio-ingressgateway \
--type=json -p="$(cat istio-ingressgateway-patch.json)" \
--dry-run=true -o yaml | kubectl apply -f -
- MultiClusterServiceをデプロイ
kubectl apply -f - <<EOF
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: bookinfo
namespace: istio-system
annotations:
beta.cloud.google.com/backend-config: '{"ports": {"80":"zone-health-check-cfg"}}'
spec:
template:
spec:
selector:
app: istio-ingressgateway
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
EOF
- BackendConfigをデプロイ
kubectl apply -f - <<EOF
apiVersion: cloud.google.com/v1beta1
kind: BackendConfig
metadata:
name: bookinfo-health-check-cfg
namespace: istio-system
spec:
healthCheck:
checkIntervalSec: 30
timeoutSec: 10
healthyThreshold: 1
unhealthyThreshold: 2
type: HTTP
port: 80
requestPath: /productpage
EOF
- MultiClusterIngressをデプロイ
kubectl apply -f - <<EOF
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
name: bookinfo-ingress
namespace: istio-system
spec:
template:
spec:
backend:
serviceName: bookinfo
servicePort: 80
EOF
結果
AnthosによってGlobalなGCLBが作成され、Ingress GatewayにルーティングされるNEGがバックエンドとして登録されている

GCLBのVIPにアクセスすることでアプリケーションが表示される

サービスメッシュのダッシュボードはこんな感じになっている(SLOモニタリングの機能もある)





試しにIstioでルーティングを変えてみる
Istioの代表的な機能である、Traffic Managementを試してみる。 今回は試しにreviewsサービスのv1に50%、v3に50%の割合でルーティングされるようにしてみる。
kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-50-v3.yaml
何度かリロードするとReviewの部分が切り替わることが分かる。
各クラスタごとにIstioのコントロールプレーンを持っているので、
マルチクラスタによって冗長化しているケースはどちらにもapplyしてあげる必要がある。
(v3は赤い星、v1は星無しで出る)

まとめ
Anthosを活用することでGKEに関しては、 マルチクラスタ構成による冗長化、ManagedなIstioの導入を組み合わせてかんたんに構築できることが分かった。 まだまだAnthosに関しては発展途上で情報も全然ない印象ではあるが、機能としては便利なので今後に期待したい。
参考
https://speakerdeck.com/jukuwa/gcpug-tokyo-istio-1-dot-5-day-anthos-service-mesh
【GCP Anthos】 Regionに跨って冗長化したKubernetsのマルチクラスタをロードバランシングする
Anthosとは?
アプリケーションを、OSSをベースにモナタイゼーションするための統括的な機能を提供するプラットフォーム。
- モナタイゼーションとは?
- マイクロサービス化
- インフラとアプリケーションの疎結合化
- サーバレス
- 自動化
- なるべくManagedへ
- モナタイゼーションとは?
Anthosが提供する機能は現時点では下記の資料が一番わかり易い
本記事の目的
本記事ではマルチクラスタを構築し、Anthosの機能を使ってクラスタにまたがって負荷分散することができるかに焦点をあてる。 GKE HubのIngress For Anthosという機能を用い実現する。 本当はマルチクラウドなクラスタで負荷分散させたかったが、GKE以外のクラスタはまだサポートされていないようだ。
Anthosへのクラスタ登録とクラスタモニタリングの仕組み
Anthosはクラスタ管理のため、各クラスタ内にGKE Connector Agentをデプロイする。
このAgentがAnthosに情報を集約し、Anthosのコントロールプレーンからの命令を各クラスタで実行することになる。
 引用: https://cloud.google.com/anthos/multicluster-management/connect/security-features
引用: https://cloud.google.com/anthos/multicluster-management/connect/security-features
Ingress For Anthosのアーキテクチャ
Anthosによるクラスタ間のロードバランシングは、Ingress For Anthosという仕組みを用いて実現する。 これは下記イメージのようなアーキテクチャになっている。
 引用: https://cloud.google.com/kubernetes-engine/docs/concepts/ingress-for-anthos
引用: https://cloud.google.com/kubernetes-engine/docs/concepts/ingress-for-anthos
登場人物について
Config Cluster
Anthos Member Cluster
- Anthosが管理するクラスタ郡のメンバー
Anthos Ingress Controller
MultiClusterService(MCS)
MultiClusterIngress(MCI)
- このリソースが作成されると、GCLBとZone NEG(MCSによって各クラスタに作成されたServiceに紐づく)が作られ、GCLBのバックエンドにはNEGが紐付けられる
動作イメージ
- MultiClusterIngressがConfig Clusterに作成されたタイミングで、Anthos Ingres Controllerが単一のGCLBを作成し、それぞれのクラスタに紐づくZone NEGをバックエンドとしてぶら下げる
Config Clusterの可用性について
当然疑問に上がってくるのは、Config Clusterの可用性はどう担保するのか?というところ。 ちなみにConfig Clusterが死ぬとMultiClusterIngressとMultiCluserServiceの設定変更ができなくなる。 つまりすでに適用した設定でのロードバランシングには影響しないが、なるべくRegionalなクラスタで運用するようなどしたほうが良い。 ただ、個人的にはサービスダウンに直結するわけではない & MultiClusterServiceとMultiClusterIngressを頻繁にメンテすることはあんまりなさそうなのでそこまでガチな可用性はなくても良さそうに感じている。 (ここにマルチクラスタで冗長化とかあんまやりたくはない...)
実際に動かしてみる
セットアップ
GKEクラスタをAnthosのクラスタメンバーに登録
gcloud container hub memberships register gke-anthos-asia \ --project=[project_name] \ --gke-cluster=asia-northeast1-a/gke-anthos-asia \ --service-account-key-file=./service-account.json
gcloud container hub memberships register gke-anthos-eu \ --project=[project_name] \ --gke-cluster=europe-north1-a/gke-anthos-eu \ --service-account-key-file=./service-account.json
ConfigクラスタをAnthosに設定
gcloud alpha container hub ingress enable \ --config-membership=projects/[project_name]/locations/global/memberships/gke-anthos-config
アプリケーションのデプロイ
- このドキュメントのリンクのセクションに従ってzoneprinterをデプロイする https://cloud.google.com/kubernetes-engine/docs/how-to/ingress-for-anthos#deployment_tutorial
結果
クラスタがAnthosのメンバーとして認識された様子(本記事の手順では割愛しているが、EKSも検証のため入れてみた)

ロードバランサーのバックエンドに自動的に作成されたNEGが紐付いている

中身はクラスタのMultiClusterServiceによって作成されたHeadlessServiceから取得されたPodのIPに紐付いている

試しにcurlしてみると、GCLBがAnyCastで最寄りのクラスタ(ネットワーク的に)にルーティングしてくれるため、常に東京クラスタの結果が帰ってくる
❯❯❯ curl 34.107.232.154/ping
{"Hostname":"34.107.232.154","Version":"1.0","GCPZone":"asia-northeast1-a","Backend":"zone-ingress-5f6ff94966-2phdz"}%
試しにAsiaクラスタを殺してみる
- deploymentを殺し、Podが存在しないようにする
❯❯❯ kubectl delete -f deployment.yaml deployment.apps "zone-ingress" deleted
❯❯❯ curl 34.107.232.154/ping
{"Hostname":"34.107.232.154","Version":"1.0","GCPZone":"europe-north1-a","Backend":"zone-ingress-5f6ff94966-7hlt7"}%
まとめ
GKEのクラスタであればかんたんにロードバランシングできるので、 クラスタ自体のアップデートをしたいが、ダウンタイムを許容したくないときやRegion障害などに活用できそうだということがわかった。 EKSなどのサポートも進めばよりいっそう便利なので対応を待望しています。
参考
これだけは知っておこうTLS
記事について
セキュリティのためにTLSを導入しようとはよく聞くが、 そもそもTLSは何を担保するものなのかを整理する。
前提として知っておくべきこと
- デジタル署名
- デジタル証明書
TLSは何を担保するのか?
下記の3つを担保する。 つまるところ、man in the middle攻撃への対策となる。
- 正真性
- 改ざんがなされていないこと
- 機密性
- 通信盗聴されても大丈夫なよう暗号化されていること
- 認証
- 正しい相手と通信をしていること
TLSの通信の流れ
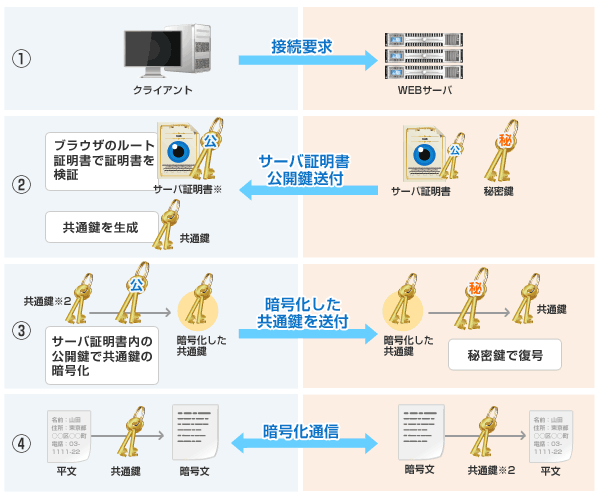 引用: SSL暗号化通信の仕組み
引用: SSL暗号化通信の仕組み
クライアント -> サーバ
- 接続要求をおこなう
サーバ -> クライアント
クライアント
サーバ
どうやって3つの目的を担保しているか?
- 認証
- デジタル証明書と共通鍵によって想定通りの相手と通信していることを担保する
- 機密性
- セッション鍵による共通鍵方式の暗号化通信により、機密性を担保する
- 正真性
- 暗号化されたデータにMessage Authentication Codeというデータのハッシュ値を付与し、これを受け取った側がハッシュ比較することで担保する
mTLSについて
厳密には上記のTLS通信だけでは認証の要件を担保できないこともある。 たとえば、企業間の外部公開されていないシステムを連携させるような、少しセキュリティ要件の高いケースなど、 サーバにアクセスしてくるクライアントもちゃんと保証したいようなケースである。 そのときに使うのが相互TLS通信というものである。(以下mTLS) mTLSはサーバに加えて、クライアントにも証明書を要求することでクライアントの身元を保証することができる。
ルート証明書、中間証明書、サーバ証明書
【2019】フリーランスエンジニア活動 振り返り
趣旨
2020年が始まるので、 2019年にやったこと、アウトプット、反省点をまとめ、翌年の指針を整理したいと思う。
前提
フリーとして働く、インフラとバックエンドを専門とするソフトウェアエンジニア。 現在は法人成りしていて、請負でベンチャー企業で開発の仕事をする傍ら、自社製品の開発に勤しんでいる。
請負でやったこと
- GAE + Go + CloudSQLを基本構成としたBtoCサービスの開発
- Stackdriver Monitoringの技術検証
- GAEで作られたパッケージシステムをスケール性を加味しGKEに移行
- 企業が使用する管理システムにAuth0をつかった認証認可の仕組みを導入
- Datadogの導入
- 機能検証
- AWS Elastic BeansTalk + Ansible
- SLOの策定、SLOにあわせてパフォーマンス改善
自社サービスとしてやったこと
- 3月 「ルーチンタイマー」iOS版リリース
- 10月下旬 「ルーチンタイマー」がツイッターで話題になりDAUが激増
- 11月中旬 急遽「ルーチンタイマー」Android版を開発開始しリリース
- 11月15日 法人設立
- おたくま経済新聞様にルーチンタイマーを紹介いただきました
- 朝日新聞様にルーチンタイマーを紹介いただきました
ブログアウトプット
振り返り
法人経営の大方針として、 ソフトウェアエンジニアとして安定したキャリアを築きつつ、余剰時間で他方面の収益源を作るべく活動している。 つまり経営の健全性としてはざっくりと
- エンジニアとしてキャリアになる経験が積めているか
- 単なる開発以外の事業の収益
を追っていこうと思っている。
エンジニアとしてキャリアを積めているか?
フリーランスが生き残るために必要な要素の一つはスペシャリティだと思っていて、 自分はバックエンド、インフラエンジニアとしての専門性を高めることに注力している。 そういった意味で、オンプレ畑で育った自分がGCPもAWSもバランス良く設計から開発、運用まで携われたのはとても良かった。 さらに、今年は運用において重要な監視について検証導入運用まで関わることができ多くの知見を吸収することができた。 今後はよりアーキテクト力を高めるために、引き続き開発から運用までまるっと経験でき、裁量の多い現場を選択して修行していくつもりである。 (運用まで視野にいれるなら一つの現場で最低1年は働きたい)
また、最近のバックエンドの開発は要件に対して過剰にk8sやマイクロサービスを導入したりとオーバーエンジニアリングが目立つ気がしている。 そこを意識した上で地に足のついたアーキテクトを目指していきたい。
単なる開発以外の事業の収益
今年はリリースしたアプリ、「ルーチンタイマー」で少し収益が出始め、大きな一歩を踏み出せた年だった。 Twitterでバズリ、メディア掲載を受けたのが利き、狙ったとおりのユーザ層に訴求することができた。 徹底的なユーザ目線、とはいいつつも実際にそれを体現するのは難しい。 だがパートナーがこういった領域が大得意で、パートナーに基本的に従えば良いものができるということを実感できた。
また、そもそも自社サービスはまずリリースさせるまでが難しい。 そういった意味で今も運用し続けられているプロダクトを2本出せたのは大きい。 成功要因は、
- 工数管理
- パートナーへの定時進捗報告
- なにかしらモチベーションをあげる技術要素を一つだけいれてみる
ということがわかったので、これから開発する新プロダクトもこれらを意識していきたい。
課題としては、良いものを作っても集客についての方法論が見いだせておらず、 バズって認知されればある程度ユーザがついてくれるのはわかったが、 そもそも流入をふやしたり、安定させるまでに至っていない。 2020年はまずリテンションを上げた上でさらに流入を増やす施策を打っていく予定である。 また、別収益源としてエンジニア養成スクール事業などにも手を出そうと考えている。
働き方の改善点
5月〜7月の間、複数の仕事を抱えすぎて体調を崩し、8月、9月はまったく働けない状態、10月以降は請負の開発を週3に減らす自体になってしまっていた。 しかし自分のキャパを把握することができ、3つ以上仕事を抱えるとあふれることが分かったので、 2020年は週4請負開発 + 週3で自社事業に取り組む方針で活動するつもりである。
なるべく一つの現場で定着して成果を出していきたいので、合わないと感じた場合は損切りの意思決定を早く持たないと精神力、時間が削れられる。 良い現場で長く働くためにもムダを減らしていくように行動しようと思う。
2020年もがんばるぞーー